Archiv für die Kategorie „Entwicklung“
 Erfahrungen mit der Google App Engine
Erfahrungen mit der Google App Engine
Seit nunmehr einigen Jahren betreibt Google ein Produkt namens „Google App Engine“. Dabei handelt es sich um ein PaaS Cloud Produkt (Platform as a Service) in dem gerade in Mode gekommenen Cloud-Bereich. Google bietet hier eine Möglichkeit an, sowohl Python, J2EE wie auch Go-Programme als Webanwendungen zu deployen. Dahinter steht nicht nur ein Container z.B. für Servlets und JSPs, sondern auch die nötige Infrastruktur in der Datenhaltungsschicht, ein MemoryCache, Cronjobs oder entsprechende dauernd laufende Instanzen wie eine Taskqueue werden einem angeboten. Das gute an diesem Service ist, dass Google ein tägliches Start-Quota verschenkt, so dass sich die App Engine ohne Risiko ausprobieren lässt.
Dasselbe habe ich getan, um Java-Applikationen zu deployen. Google stellt an dieser Stelle ein relativ komforables Plugin für Eclipse bereit, mit welchem sich die Applikationen sowohl lokal testen lassen als auch direkt per Mausklick in die Cloud hochladen lassen. Dies sieht in Eclipse Juno 4.2 so aus (um den Screenshot zu vergrößern, bitte auf das Bild klicken):

Der Funktionsumfang ist sehr umfangreich. So lassen sich nicht nur JSPs oder Servlets wie standardmäßig entwickeln, sondern es sind sogar JDO oder gar JPA Features vorhanden. Um eine möglichst kleine Applikation zu testen, wurde eine Testapplikation geschrieben, die zunächst nur Dummyeinträge in den lokalen Big-Table-Storage von Google einfügt, von dem Google ein Gigabyte Freivolumen verschenkt.
Was bei einer Belastung dieser Applikation auffällt, ist, dass das Freivolumen doch nicht so hoch ist, wie eigentlich angenommen, sondern dass relativ schnell einem die Freianfragen an die Big-Table-Datenbank ausgehen. Es bietet sich dann ein Bild wie das folgende in der Quota-Übersicht von Google:

Auch ein Lesen lässt schnell den Quota auf Null schrumpfen (hier mit einer größeren Datenbank, die über mehrere Wochen angelegt worden ist):

Interessanterweise tun sich beim Schreiben von Datensätzen sowohl der veraltete Master/Slave-Store wie auch der High Replication Store nicht viel. Beide sind ungefähr zum gleichen Moment Over-Quota. Die Master/Slave-Engine erreicht das Quota in einem Test bei 3179 Datenbankanfragen, die High Replication nach 3189. Selbstverständlich lässt sich hier dem eingeschränkten Quota mit Geld Abhilfe schaffen.
Abhilfe von dem Bigtable-Problem schafft das Google Cloud SQL Angebot, welches eine SQL-Datenbank für den Entwickler bereit stellt. Auf diese kann direkt aus der Google App Engine zugegriffen werden. Leider ist diese Datenbanklösung auf einen relativ hohen Tagespreis umgestellt worden.
Man merkt, dass sich die Google Cloud Lösungen für kleinere nicht so häufig besuchte Projekte sehr gut eignen, vor allen Dingen, wenn es wenig Datenbankabfragen gibt. Wird dieses Produkt jedoch für größere Webseiten eingesetzt, so kann dies relativ schnell sehr teurer werden.
Große Pluspunkte sammelt die Engine in ihrer Stabilität und Standardkonformität ein. Wenn Sie dabei sind, ein Projekt starten zu wollen, so können Sie getrost mit der Google App Engine anfangen und hierauf entwickeln. Sobald die Zeit kommt, wo Sie aus der App Engine heraus wachsen, können Sie sich entscheiden, diese entweder weiter zu nutzen und einen höheren Preis zu bezahlen und dafür jedoch auch ihre Features wie die Lastverteilung und die Einsparung der Serveradministration zu nutzen, oder Sie können auf ein eigenes Serversystem umziehen. Google App Engine ermöglicht es Ihnen sowohl in der Bigtable-Variante wie auch in der Google Cloud SQL-Variante Ihre Daten jederzeit in und aus der Cloud zu portieren.
Für mich ein sehr gelungenes Produkt für Start-Up-Projekte. Ich werde weiter dabei bleiben.
Projekte aus Eclipse in ZIP-Dateien exportieren
Das Projekt befindet sich innerhalb des Workspaces (beispielsweise hier das Projekt AufgabeAP3):
Mit einem rechten Mausklick auf das Projekt öffnen Sie das Kontextmenü und wählen „Export“:

In dem sich nun öffnenden Fenster wählen Sie „Archive-File“:

In dem sich nun öffnenden Fenster ist das Projekt schon vorselektiert. Bitte stellen Sie sicher, dass hier das komplette Projekt selektiert ist:

Wählen Sie nun unter Optionen „Save in zip format“ und „Create directory structure for files“ sowie „Compress the contents of the file”. Dies sollte normalerweise schon voreingestellt sein.
Vergessen Sie nicht unter „To archive file“ die ZIP-Datei anzugeben, in welche das Projekt gespeichert werden soll.
Nach dem Klick auf „Finish“ befindet sich das gepackte Projekt im entsprechenden Verzeichnis.
Dieses Video zeigt den Export noch einmal (auf YouTube oder Vollbild im Player klicken, um es in Großansicht zu sehen):
Projekte aus ZIP-Dateien in Eclipse importieren
Durch Rechts-Klick auf den leeren Workspace öffnet sich wieder das Kontekt-Menü. Wählen Sie „Import“ -> „Import…“

Im folgenden Fenster wählen Sie „General“ -> „Existing Projects into Workspace“

Wählen Sie in dem folgenden Fenster „Select Archive File“ und wählen Sie über den Browse-Button rechts daneben das entsprechende ZIP-File aus. Unter „Projects“ werden Ihnen die enthaltenen Projekte in diesem ZIP-File angezeigt:

Mit einem Klick auf „Finish“ werden die Projekte importiert.
Dieses Video zeigt dieses Vorgehen nochmals im Schnelldurchgang (auf YouTube oder Vollbild im Player klicken, um es in Großansicht zu sehen):
Refactoring mit Eclipse Step4Step
Im Folgenden möchte ich gerne einige der Refactoring-Funktionalitäten von Eclipse demonstrieren. Für das Refactoring wird ein JUnit-Test, so wie es Ziel der eXtreme-Programming-Methodik ist, benutzt, um zu prüfen, ob die originale Funktionalität noch vorhanden ist. Die Anleitung demonstriert die Fähigkeiten der Eclipse-Entwicklungsumgebung das Rafactoring mit JUnit zu unterstützen, zeigt jedoch im letzten Schritt auch Grenzen auf, so wieder ein händisches Vorgehen vonnöten ist.
Vielfach wurden die Sourcen der Anleitung erwünscht. Das Projekt zu Beginn befindet sich in vorRefactoring.zip, das Projekt nach allen Refactoringschritten befindet sich in nachRefactoring.zip.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
/** * AdressAusgabe.java * Klasse zur Ausgabe eines Adressbucheintrages * @author Christoph Tornau * */ public class AdressAusgabe { public String name; public String vorname; public String strasse; public String plz; public String ort; public AdressAusgabe(String name, String vorname, String strasse, String plz, String ort ) { this.name = name; this.vorname = vorname; this.strasse = strasse; this.ort = ort; this.plz = plz; } public String toString() { String output = ""; output += ("***"); output += (name); for (int i= name.length() + 3; i<30; i++) output += ("*"); output += ("\n"); output += ("***"); output += (vorname); for (int i= vorname.length() + 3; i<30; i++) output +=("*"); output += ("\n"); output += ("***"); output += (strasse); for (int i= strasse.length() + 3; i<30; i++) output += ("*"); output += ("\n"); output += ("***"); output += (plz); for (int i= plz.length() + 3; i<30; i++) output +=("*"); output += ("\n"); output += ("***"); output += (ort); for (int i= ort.length() + 3; i<30; i++) output +=("*"); output += ("\n"); output += ("***"); output += (""); for (int i= "".length() + 3; i<30; i++) output +=("*"); output += ("\n"); return output; } /** * Main method * @param args */ public static void main(String[] args) { AdressAusgabe myAdresse1 = new AdressAusgabe ("Maier","Hans", "Musterstrasse 1","11111","Musterstadt"); System.out.println(myAdresse1); AdressAusgabe myAdresse2 = new AdressAusgabe ("Gustav","Morgan", "Pappelallee 15","53122","Bonn"); System.out.println(myAdresse2); } } |
An der Beispielklasse fallen uns folgende Bad-Smells sofort auf:
- Der Code für die Ausgabe ist in mehrfacher Ausführung vorhanden.
- Anscheindend wurde darauf verzichtet in eine extra Datenklasse zu kapseln. Alles ist in einer Klasse geschrieben. Man sollte auf jeden Fall trennen.
- Felder können von außen gelesen und geschrieben werden. Es gibt keine Getter- und Setter-Methoden.
Der Code verfügt über einen JUnit-Test, wie folgender Screenshot zeigt:
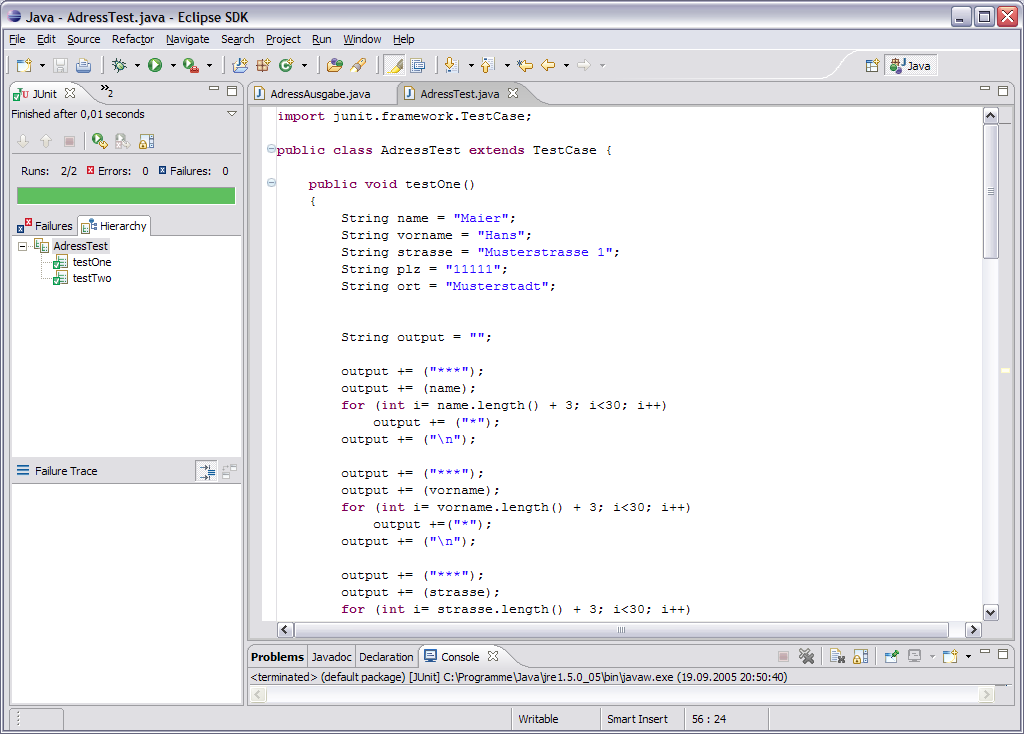
Wir führen nun folgende Refactorings nacheinander durch. Nach den einzelenen Schritten führen wir jedesmal einen Test mit JUnit durch. Ds Refactoring kann nur fortgeführt werden, wenn der Balken grün bleibt. Ansonsten haben wir einen Fehler gemacht. Hier der grüne Balken:
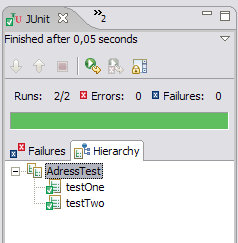
1. Extract Method:
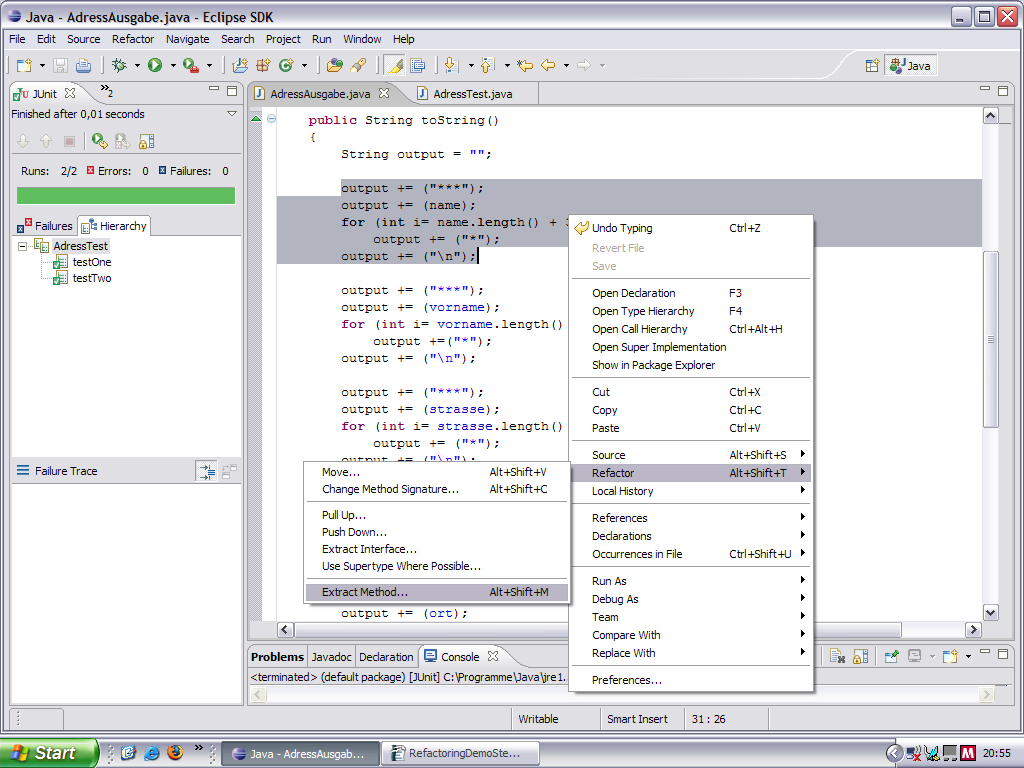
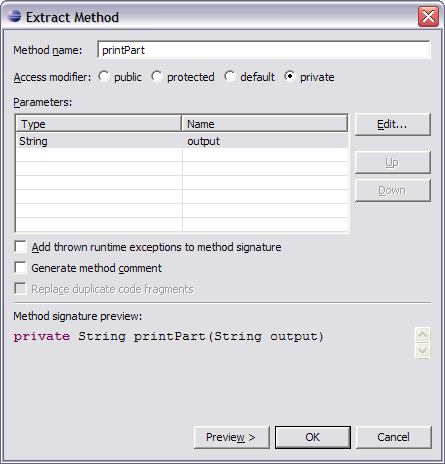
Nun entsteht eine neue Methode im Code:
|
1 2 3 4 5 6 7 8 |
private String printPart(String output) { output += ("***"); output += (name); for (int i= name.length() + 3; i<30; i++) output += ("*"); output += ("\n"); return output; } |
Wir sehen, dass diese Methode als „private“ deklariert ist und den output-String sowohl bekommt als auch wieder ausgibt. Nach dem Extrahieren der Methode können wir die JUnit-Tests ausführen, um zu prüfen, ob die Programmfunktionalität zerstört worden ist.
2. Ändern des Methoden-Aufrufs
Wir wollen den String, welcher übergeben wird, in die Ausgabe statt „name“ einbauen. Gleichzeitig wollen wir den Originalstring nicht mehr übergeben:
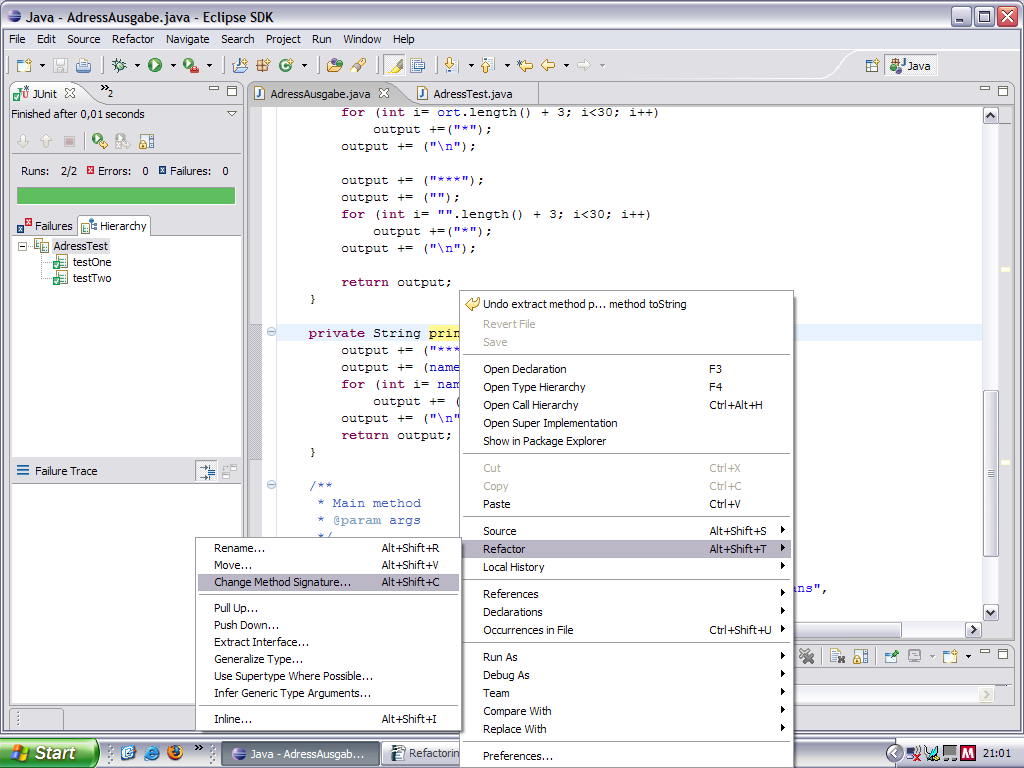
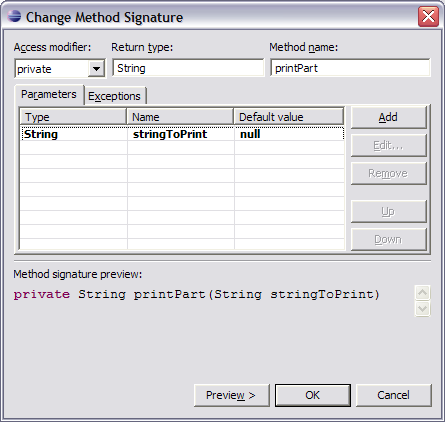
Nun gibt es einige Fehlermeldungen:
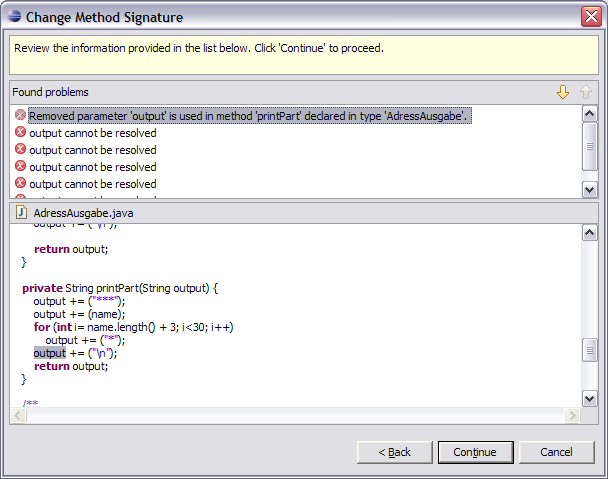
Wir ignorieren diese und ändern den Code per Hand um:
|
1 2 3 4 5 6 7 8 9 10 |
private String printPart(String stringToPrint) { String output = ""; output += ("***"); output += (stringToPrint); for (int i= stringToPrint.length() + 3; i<30; i++) output += ("*"); output += ("\n"); return output; } |
Ebenso ändern wir den Methodenaufruf per Hand um in
|
1 |
output = printPart(name); |
Nun können wir per Hand die hinzugefügte Methode ändern und elimieren so den dupplizierten Code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public String toString() { String output = ""; output += printPart(name); output += printPart(vorname); output += printPart(strasse); output += printPart(plz); output += printPart(ort); output += printPart(""); return output; } |
Nachdem wir dies durchgeführt haben, müssen wir wiederum die JUnit-Tests ausführen und erhalten als Ergebnis, dass der Code immernoch lauffähig ist.
3. Neue Klasse erzeugen und Methoden bewegen
Nun möchten wir gerne eine Datenklasse erzeugen, um die Daten von der Hauptklasse abzutrennen:
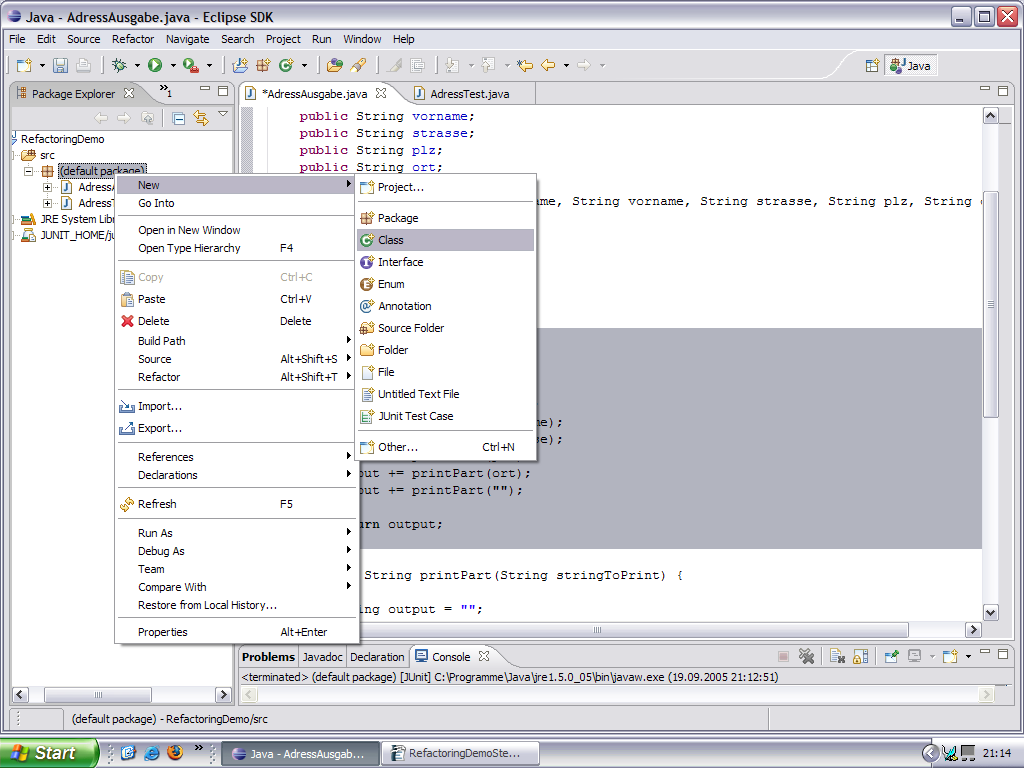
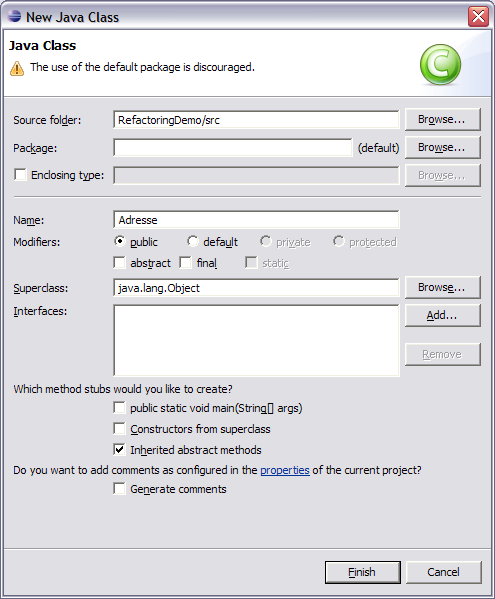
Wir bewegen zunächst die Methode printPart, nachdem wir deren Methoden Signatur etwas geändert haben:
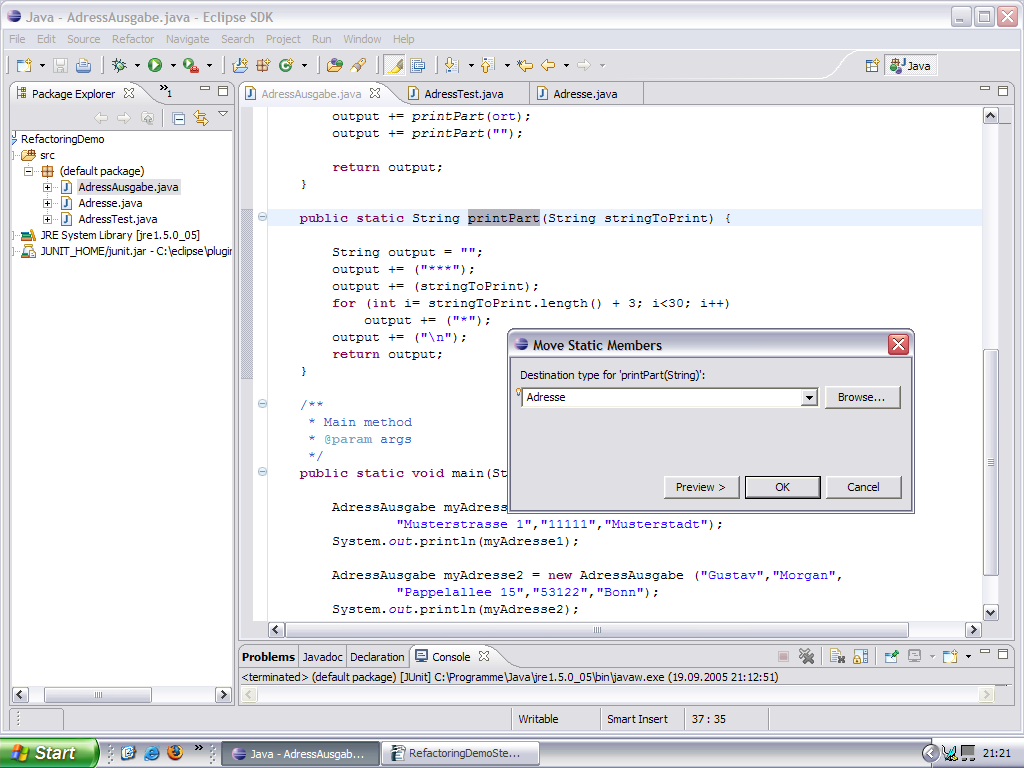
Unser Code ändert sich automatisch mit
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public String toString() { String output = ""; output += Adresse.printPart(name); output += Adresse.printPart(vorname); output += Adresse.printPart(strasse); output += Adresse.printPart(plz); output += Adresse.printPart(ort); output += Adresse.printPart(""); return output; } |
Leider können wir die restlichen Methoden mit Eclipse nicht automatisch verschieben, weshalb wir sie per Hand verschieben, so dass die neue Klasse wie folgt aussieht:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
public class Adresse { public String name; public String vorname; public String strasse; public String plz; public String ort; public Adresse(String name, String vorname, String strasse, String plz, String ort ) { this.name = name; this.vorname = vorname; this.strasse = strasse; this.ort = ort; this.plz = plz; } public String toString() { String output = ""; output += Adresse.printPart(name); output += Adresse.printPart(vorname); output += Adresse.printPart(strasse); output += Adresse.printPart(plz); output += Adresse.printPart(ort); output += Adresse.printPart(""); return output; } public static String printPart(String stringToPrint) { String output = ""; output += ("***"); output += (stringToPrint); for (int i= stringToPrint.length() + 3; i<30; i++) output += ("*"); output += ("\n"); return output; } } |
Hier hinkt nun unser JUnit-Test. Der Grund hierfür ist, dass sich der Klassenname der zu prüfenden Klasse geändert hat, da die Funktionalität per Hand verschoben worden ist. In diesem Fall dürfen wir jedoch unseren JUnit-Test anpassen, indem wir dort den Klassennamen ändern.
Wir setzen die Methode printPart wieder privat.
Noch immer sind die Felder „public“ Wir wenden Encapsulate Field an.
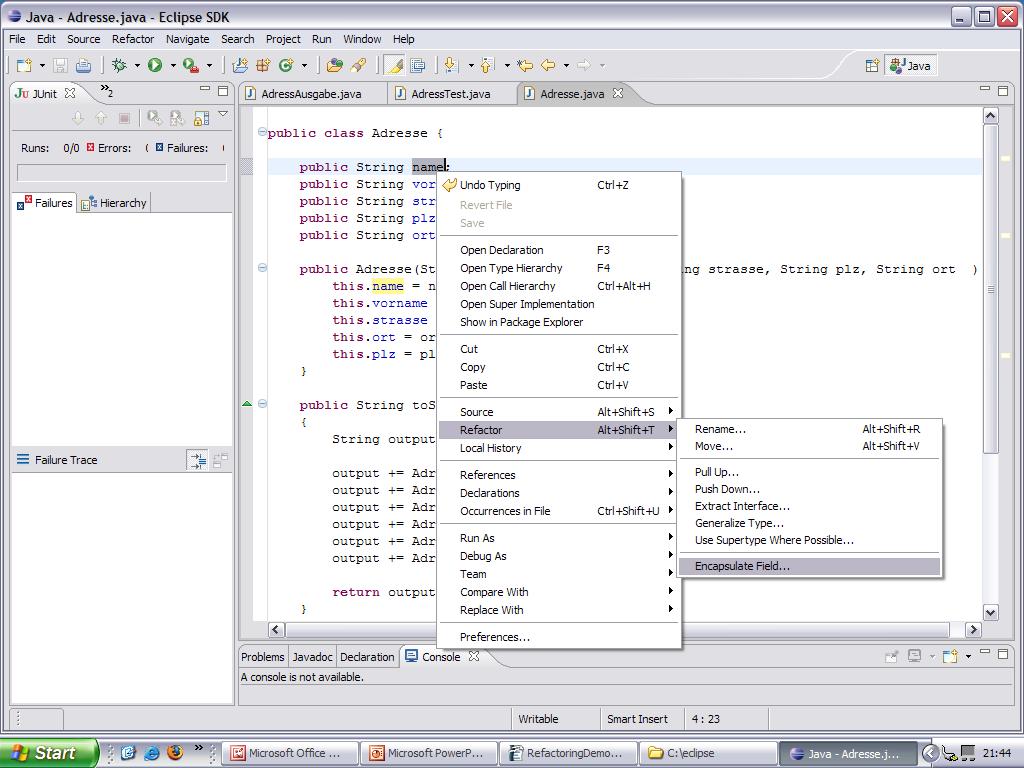
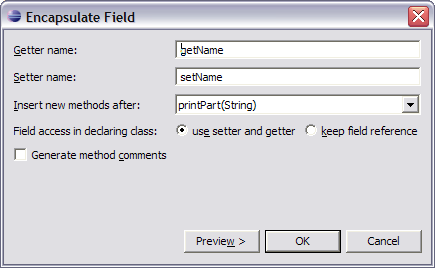
Wir führen die JUnit-Tests nochmals durch. Wir sehen, dass der Balken weiter grün ist. Das Refactoring war erfolgreich und wir haben viel schöneren Code erhalten.