Archiv für die Kategorie „Entwicklung“
 Videokurs: Java Persistence API mit Hibernate und der Oracle DB
Videokurs: Java Persistence API mit Hibernate und der Oracle DB
Die Java Persistence API (abgekürzt: JPA) bietet die Möglichkeit komfortabel Daten aus der der Welt der Objektorientierung, d.h. aus Deinen Java-Programmen, in die Welt der relationalen Datenbanken zu transportieren und diese von dort wieder abholen. In der freien Wildbahn findet man kaum ein Programm, welches ohne eine Datenbank auskommt. Besonders in großen Unternehmen wachsen die Datenbanken in den Terrabyte-Bereich. Die JPA bietet einen einfachen Zugang zu diesen Datenbanken, indem in den Java-Klassen Annotationen verwendet werden, die der JPA mitteilen, wie die Klassenvariablen in der Datenbank abzubilden sind. Die JPA wertet diese Annotationen aus und ermöglicht eine automatische Synchronisation zwischen Java-Modell und Datenbank.
Natürlich steckt der Teufel im Detail. So passen objektorientierte Welt und relationale Welt konzeptuell an einigen Stellen nicht zusammen, was man als „Impedance Mismatch“ bezeichnet. Um diesen Impedance Mismatch (zu Deutsch auch objektrelationale Unverträglichkeit) zu überwinden, sind detaillierte Kenntnisse sowohl in der Java-Welt wie auch in der relationalen Datenbankwelt nötig. Die JPA bietet Konzepte an, die nutzbar sind, um in seinem Programm diese Unverträglichkeit zu überwinden. Der Kurs hört nicht bei einfacher Übertragung auf, sondern schaut sich diese Schwierigkeiten im Detail an, damit Du gerüstet bist:
- Ein einfaches Objekt wird in die Datenbank gebracht. Die Einstellungen für die einzelnen Variablentypen werden besprochen.
- SQL wird in einem integrierten Crash-Kurs wiederholt, damit Du besonders in der Lage bist, Joins auf der Datenbank durchzuführen, die auch von JPA transparent durchgeführt werden.
- Unterschiedliche Beziehungen (1:1, 1:N und N:M) unidirektional und bidirektional werden aufgebaut.
- Möglichkeiten der Abbildung von Vererbungshierarchien aus der objektorientierten Welt werden erklärt.
- und weiteres…
Innerhalb des Kurses erwartet Dich viel Praxis. Anhand eines kleinen Praxisprojektes werden die theoretischen Grundlagen am lebenden Beispiel ausprobiert.
- Das Praxisprojekt ist eine CRUD-Verwaltung von Personen. Es kann jedoch auf beliebige Daten von Dir umgebaut werden.
Es handelt sich um eine Java SE-Desktopapplikation, welche Java FX als GUI-Framework nutzt. - Innerhalb des Kurses gehen wir jedoch auf darauf ein, wie auf einem Applicationserver im Java EE-Umfeld, konkret auf einem WildFly-Applikation-Server, der sich an den JBoss-Server anlehnt, die JPA genutzt werden kann. Hierbei berühren wir auch den Bereich der Enterprise Java Beans (EJB) und wie sie mit der JPA genutzt werden können.
- Der Kurs ist ein Expertenkurs. Das bedeutet, er hat ein hohes Niveau und geht ins Detail. Als Voraussetzung für den Kurs sind jedoch nur Java-Kenntnisse erforderlich. Alle anderen Kenntnisse werden Dir in dem Kurs vermittelt.
Buchbar ist der Kurs unter dem folgenden Link für nur €10:

Java Persistence API mit Hibernate und der Oracle DB
Manchmal steht man vor dem Problem, dass ein Port, den man unter Windows gerade benutzen möchte, blockiert ist. Das bedeutet, ein anderer Prozess benutzt diesen Port momentan und man kann seinen eigenen Dienst nicht starten. In der Eclipse IDE wird man beispielsweise mit der folgenden Fehlermeldung konfrontiert:
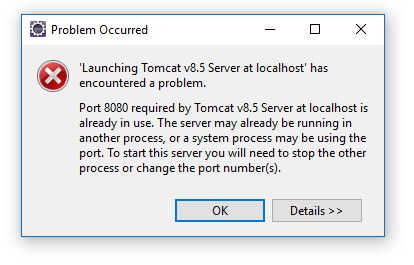
Es ist wie folgt möglich, den Dienst zu finden, der den Port blockiert und diesen dann zu beenden:
- Kommandozeile ausführen: Im Windowsstartmenü findet sich die Kommandozeile unter „Windows-System“ -> „Eingabeaufforderung“. Dies muss durch ein Klicken der rechten Maustaste im Administratormodus gestartet werden:
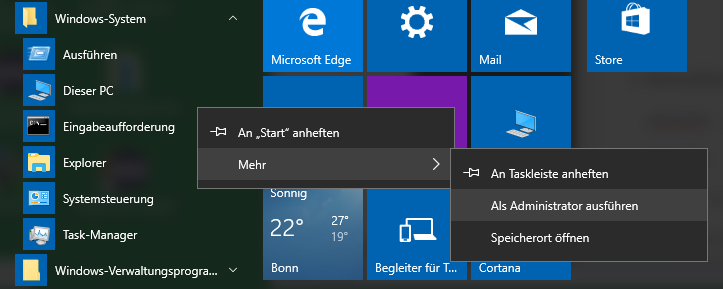
- Herausfinden, welche Prozess-ID der Prozess trägt, durch Eingabe folgenden Befehls auf der Kommandozeile:
1netstat -aon | findstr /r :8080
Ausgabe:
1TCP 0.0.0.0:8080 0.0.0.0:0 ABHOEREN 3572
Die letzte Ziffer, in diesem Beispiel 3572, ist die Prozess-ID. - Den Prozess mit seinen Informationen anzeigen, indem Folgendes auf der Kommandozeile eingegeben wird:
1tasklist /FI "PID eq 3572" /FO TABLE
Ausgabe
123Abbildname PID Sitzungsname Sitz.-Nr. Speichernutzung========================= ======== ================ =========== ===============TNSLSNR.EXE 3572 Services 0 3.232 K - Den Prozess mit folgendem Befehl auf der Kommandozeile beenden
1taskkill /pid 3572 /f
Ausgabe ist
1ERFOLGREICH: Der Prozess mit PID 3572 wurde beendet.Alternativ kann man auch versuchen, dem Prozess sanfter zu beenden, indem man den Dienst sucht, der diesen Prozess ausmacht und diesen dann herunterfährt. Zusätzlich ist ein Finden des Prozesses über den Taskmanager möglich.
Eclipse – Entwicklungsumgebung für Java
Eclipse ist eine der am weitesten verbreiteten Entwicklungsumgebungen, die besonders aber nicht nur für die Programmiersprache Java zum Einsatz kommt. Im Folgenden findet sich ein kurzer Videorundgang, um die Basisfeatures dieser Entwicklungsumgebung zu erklären:
| 01: Einführung in die Videoreihe |  In dieser Videoreihe geht es um die Vorstellung der Eclipse Entwicklungsumgebung. Dabei soll nicht erklärt werden, mit Eclipse Java-Programme zu erstellen, sondern ein grundlegendes Verständnis des Aufbaus der IDE soll vermittelt werden, so dass sie als ein Werkzeug in der Entwicklung von Software effektiv eingesetzt werden kann. In dieser Videoreihe geht es um die Vorstellung der Eclipse Entwicklungsumgebung. Dabei soll nicht erklärt werden, mit Eclipse Java-Programme zu erstellen, sondern ein grundlegendes Verständnis des Aufbaus der IDE soll vermittelt werden, so dass sie als ein Werkzeug in der Entwicklung von Software effektiv eingesetzt werden kann. |
00:01:48 |
| 02: Installation von Java und der Eclipse Entwicklungsumgebung unter Windows |  Sowohl Java wie auch Eclipse werden heruntergeladen und installiert. Java ist unter http://www.oracle.de verfügbar. Eclipse ist unter https://www.eclipse.org herunterladbar. Sowohl Java wie auch Eclipse werden heruntergeladen und installiert. Java ist unter http://www.oracle.de verfügbar. Eclipse ist unter https://www.eclipse.org herunterladbar. |
00:09:28 |
| 03: Perspektiven und Views |  Innerhalb der Eclipse IDE werden die Perspektiven und Views erklärt. Unterschiedliche Perspektiven werden vorgestellt, wie sich diese öffnen lassen. Der Ort, an welchem neue Views einer vorhandenen Perspektive hinzugefügt werden können, wird gezeigt. Zum Abschluss wird gezeigt, wie ein Webbrowser eingefügt werden kann und dieser innerhalb der Darstellung der Perspektive verschoben werden kann. Innerhalb der Eclipse IDE werden die Perspektiven und Views erklärt. Unterschiedliche Perspektiven werden vorgestellt, wie sich diese öffnen lassen. Der Ort, an welchem neue Views einer vorhandenen Perspektive hinzugefügt werden können, wird gezeigt. Zum Abschluss wird gezeigt, wie ein Webbrowser eingefügt werden kann und dieser innerhalb der Darstellung der Perspektive verschoben werden kann. |
00:05:52 |
| 04: Anlegen eines Java-Projektes |  Ein Hello-World-Projekt wird innerhalb von Eclipse in Java erstellt, um die Wizards, die Eclipse hierzu bereit stellt, zu demonstrieren. Auch der Outline wird behandelt. Dann wird das Eclipse-Projekt gestartet. Ein Hello-World-Projekt wird innerhalb von Eclipse in Java erstellt, um die Wizards, die Eclipse hierzu bereit stellt, zu demonstrieren. Auch der Outline wird behandelt. Dann wird das Eclipse-Projekt gestartet. |
00:08:05 |
| 05: Auto-Completion und Korrekturhilfen |  Innerhalb dieses Videos wird das Feature der Auto-Vervollständigung von Eclipse demonstriert. Weiterhin wird gezeigt, wie die Korrekturhilfen von Eclipse im allgemeinen funktionieren. Es ist dem Nutzer von Eclipse im Detail überlassen, beide Features der Auto-Completion und Korrektur zu nutzen und deren Funktionalität an vielen unterschiedlichen Stellen kennenzulernen. Dieses kurze Video bietet nur einen kleinen Einblick. Innerhalb dieses Videos wird das Feature der Auto-Vervollständigung von Eclipse demonstriert. Weiterhin wird gezeigt, wie die Korrekturhilfen von Eclipse im allgemeinen funktionieren. Es ist dem Nutzer von Eclipse im Detail überlassen, beide Features der Auto-Completion und Korrektur zu nutzen und deren Funktionalität an vielen unterschiedlichen Stellen kennenzulernen. Dieses kurze Video bietet nur einen kleinen Einblick. |
00:06:51 |
| 06: Navigieren im Java-Code in Eclipse |  Navigieren zwischen unterschiedlichen Klassen im Java-Code, Direkteinsprung zu Methoden, Öffnen eines Typs über das Menü, Verständnis des Outlines einer Java-Klasse und Darstellung von Klassenhierarchien Navigieren zwischen unterschiedlichen Klassen im Java-Code, Direkteinsprung zu Methoden, Öffnen eines Typs über das Menü, Verständnis des Outlines einer Java-Klasse und Darstellung von Klassenhierarchien |
00:10:30 |
| 07: Debugging |  Innerhalb von Eclipse befindet sich ein mächtiges Debugging-Werkzeug um Java-Programme in ihrer Ausführung zu beobachten. Genutzt wird dieses Werkzeug zum Nachvollziehen von Programmabläufen und zur Fehlerauffindung. Im Video geht es um folgende Themen: Setzen von Breakpoint und Wechsel in die Debugging-Perspektive von Eclipse, Erklärung der unterschiedlichen Steps wie Step Into, Step Over und Step Back. Inspect und Watch erläutert. Innerhalb von Eclipse befindet sich ein mächtiges Debugging-Werkzeug um Java-Programme in ihrer Ausführung zu beobachten. Genutzt wird dieses Werkzeug zum Nachvollziehen von Programmabläufen und zur Fehlerauffindung. Im Video geht es um folgende Themen: Setzen von Breakpoint und Wechsel in die Debugging-Perspektive von Eclipse, Erklärung der unterschiedlichen Steps wie Step Into, Step Over und Step Back. Inspect und Watch erläutert. |
00:12:37 |
| 08: Refactoring |  Eclipse hat anders als ein reiner Texteditor ein Verständnis über den vorliegenden Java-Code. Aus diesem Grunde ist es auch möglich, Teile von Methoden als neue Methoden herauszuziehen, Klassen umzubenennen oder Methoden in Klassenhierarchien zu verschieben. Diese drei Refactoring-Methoden stellt dieses Video vor. Weitere Refactoring-Methoden auszuprobieren ist dem Zuschauer überlassen. Eclipse hat anders als ein reiner Texteditor ein Verständnis über den vorliegenden Java-Code. Aus diesem Grunde ist es auch möglich, Teile von Methoden als neue Methoden herauszuziehen, Klassen umzubenennen oder Methoden in Klassenhierarchien zu verschieben. Diese drei Refactoring-Methoden stellt dieses Video vor. Weitere Refactoring-Methoden auszuprobieren ist dem Zuschauer überlassen. |
00:07:21 |
| 09: Der Marketplace |  Der Marketplace ist ein Ort in Eclipse, um zahlreiche Plugins in das System zu installieren. Das Video gibt einen kleinen Rundgang um die Plugins für SVN, JBoss, Python, Android Development etc. Auch das manuelle Eintragen von Eclipse Sites wird besprochen sowie das Update von Eclipse. Der Marketplace ist ein Ort in Eclipse, um zahlreiche Plugins in das System zu installieren. Das Video gibt einen kleinen Rundgang um die Plugins für SVN, JBoss, Python, Android Development etc. Auch das manuelle Eintragen von Eclipse Sites wird besprochen sowie das Update von Eclipse. |
00:15:29 |
| 10: Git als Versionskontrollsystem |  In diesem Video zeige ich, wie ein lokales Git-Repository innerhalb von Eclipse angelegt wird, das Projekt in dieses eingefügt wird und schließlich das gesamte Repository auf GitHub hochgeladen wird. Das GitHub-Repository befindet sich unter https://github.com/ctornau/Eclipse-Walkthrough während GitHub selbst unter https://github.com verfügbar ist. In diesem Video zeige ich, wie ein lokales Git-Repository innerhalb von Eclipse angelegt wird, das Projekt in dieses eingefügt wird und schließlich das gesamte Repository auf GitHub hochgeladen wird. Das GitHub-Repository befindet sich unter https://github.com/ctornau/Eclipse-Walkthrough während GitHub selbst unter https://github.com verfügbar ist. |
00:17:26 |
| 11: Checkouts mit Git unter Eclipse |  Mit dem in Eclipse eingebautem Git-Client wird ein Checkout (ein Pull) eines Projektes von einem entfernten Repository-Server durchgeführt (in diesem Fall ist es GitHub). Änderungen werden an dem Projekt durchgeführt und wieder gepusht und auch ein Branch angelegt und gepusht. Mit dem in Eclipse eingebautem Git-Client wird ein Checkout (ein Pull) eines Projektes von einem entfernten Repository-Server durchgeführt (in diesem Fall ist es GitHub). Änderungen werden an dem Projekt durchgeführt und wieder gepusht und auch ein Branch angelegt und gepusht. |
00:08:59 |
| 12: Projekte exportieren |  Wie ist es möglich, ein Eclipse Projekt in eine Archivdatei zu schreiben und beispielsweise einfach per Email zu versenden? Dieses kleine Video zeigt die Arbeitsschritte. Wie ist es möglich, ein Eclipse Projekt in eine Archivdatei zu schreiben und beispielsweise einfach per Email zu versenden? Dieses kleine Video zeigt die Arbeitsschritte. |
00:02:59 |
| 13: Projekt importieren |  Innerhalb einer Archiv-Datei – beispielsweise einer ZIP-Datei – ist ein Eclipse-Projekt empfangen worden. Ein einfaches Auspacken dieser Datei und verschieben des Extraktes in das Workspaceverzeichnis reicht nicht. Dieses Video zeigt, wie sich innerhalb von Eclipse auf einfache Art und Weise diese Projekte importieren lassen. Innerhalb einer Archiv-Datei – beispielsweise einer ZIP-Datei – ist ein Eclipse-Projekt empfangen worden. Ein einfaches Auspacken dieser Datei und verschieben des Extraktes in das Workspaceverzeichnis reicht nicht. Dieses Video zeigt, wie sich innerhalb von Eclipse auf einfache Art und Weise diese Projekte importieren lassen. |
00:03:29 |
| 14: Arbeiten mit JUnit |  Um zu prüfen, ob ein Programm genau das tut, was es tun soll, sind Tests besonders nützlich. Sie geben dem Programmierer die Möglichkeit an die Hand, nicht imperativ zu denken, sondern aus dem Blickwinkel der erwarteten Ausgaben bei definierten Eingaben auf die Software zu schauen. Bei diesem Blickwinkel werden viele Fehler gefunden. Eclipse hat JUnit, ein Tool zum Testing, direkt integriert. So muss der Entwickler keinen Wechsel zwischen verschiedenen Applikationen machen und kann Tests komfort Um zu prüfen, ob ein Programm genau das tut, was es tun soll, sind Tests besonders nützlich. Sie geben dem Programmierer die Möglichkeit an die Hand, nicht imperativ zu denken, sondern aus dem Blickwinkel der erwarteten Ausgaben bei definierten Eingaben auf die Software zu schauen. Bei diesem Blickwinkel werden viele Fehler gefunden. Eclipse hat JUnit, ein Tool zum Testing, direkt integriert. So muss der Entwickler keinen Wechsel zwischen verschiedenen Applikationen machen und kann Tests komfort |
00:08:57 |
Videokurs: Java Server Faces (JSF) mit CDI
Die Java Server Faces (JSF) sind eine Ablösung der Java Server Pages (JSP). Sie spielen ihre Vorteile besonders dann aus, wenn es um formularbasierte Webanwendungen geht, die in vielen Bereichen genutzt werden.
Java Server Faces ermöglichen eine automatische Synchronisation zwischen den Formularfeldern auf der HTML-Seite und einer im Backend sich befindlichen Backing-Bean. Dabei werden die Eingabefelder konvertiert und validiert. Mit Hilfe eines solchen Vorgehens wird die Verarbeitung solcher Eingabemasken wesentlich vereinfacht. Diese Synchronisation kann nicht nur bei einem einmaligen Absenden des Formulares durchgeführt werden, sondern sie kann über Hintergrund-AJAX-Requests durchgeführt werden, so dass der Benutzer eine unmittelbare Auswirkung seiner Eingabe sehen kann.
Zusätzlich verfügen die Java Server Faces über eine mächtige Templating-Engine wie auch über die Definition einer Navigation.
Der folgende Videokurs führt intensiv in die Java Server Faces (JSF) ein und stellt auch die Contexts and Dependency Injection (CDI) vor, die in die Java Server Faces gerade Einzug hält. Über den untenstehenden Link ist der Kurs zu einem Rabattpreis buchbar:
 Java Server Faces (JSF) mit CDI
Java Server Faces (JSF) mit CDIFolgendes Video erläutert den Kurs noch einmal genauer und ist gleichzeitig auch ein Beispiel, in welchem Format der Videokurs aufgenommen ist:
Die Java Enterprise Edition (Java EE) ist eine Plattform, auf welcher viele Hochlast-Webanwendungen betrieben werden. Dementsprechend herrscht auch immer eine hohe Nachfrage an Entwicklern, die dieser Plattform mächtig sind.
Der von mir angebotene Kurs bietet einen Einstieg in diese Plattform. Er erklärt den Umgang mit Servlets und JSPs umfassend. In praktischen Beispielen wird der Apache Tomcat als Server und die Eclipse IDE als Entwicklungsumgebung eingesetzt. Dabei geht es vor allen Dingen auch um die vielen Möglichkeiten innerhalb von Eclipse, die die Entwicklung in der Java Enterprise Edition (Java EE) unterstützen.
Unter folgendem Couponlink ist es möglich, den Kurs mit einem Rabatt zu buchen:
 Java EE mit Tomcat und Eclipse
Java EE mit Tomcat und EclipseIn dem folgenden Video erkläre ich die Vorzüge dieses Kurses. Das Video selbst ist ein Beispiel, wie das Videokursmaterial aufgebaut ist:
Das Visitor-Pattern / Besucher-Muster
Idee des Patterns
Die Idee des Patterns ist es, dass Besuchs-Objekte zu besuchende Objekte „besuchen”. Dabei hängen normalerweise die zu besuchenden Objekte miteinander verknüpft im Speicher, so dass sie traversiert werden können. Ein Besuch sieht so aus, dass eine accept()-Methode auf dem zu besuchenden Objekt aufgerufen wird, in deren Übergabewerten das Besuchs-Objekt selbst übergeben wird. Das zu besuchende Objekt ruft dann mit sich selbst als Parameter eine visit()-Methode im Besuchs-Objekt auf. In dieser Methode findet dann erst die eigentliche Logik eines Algorithmusses statt. Es findet also ein doppelter Aufruf statt.
Dieser doppelte Aufruf ist in folgendem Sequenzdiagramm dargestellt:
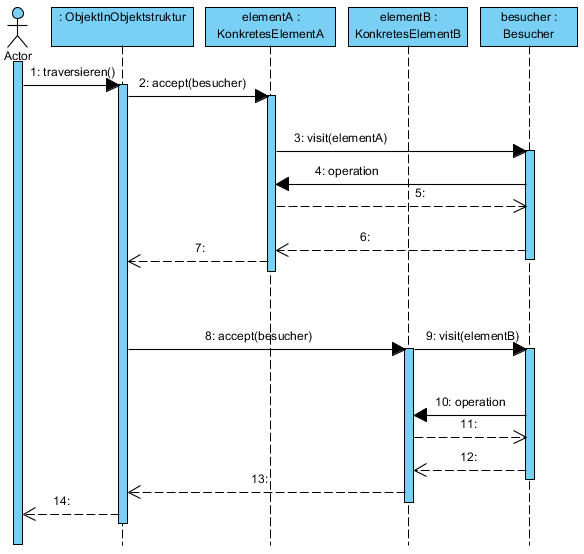
Das Visitorpattern kommt häufig im Compilerbau zur Anwendung. Hier wird ein AST des Programmes aufgebaut, welcher eine Baumstruktur des zu kompilierenden Programmes im Speicher darstellt. Dieser Baum kann dann mit Hilfe des Visitor-Patterns traversiert werden. Dabei stellen die Elemente des ASTs die zu besuchenden Objekte dar. Die Besucher implementieren Algorithmen, die Informationen des ASTs verarbeiten.
Allgemeines Klassendiagramm des Patterns
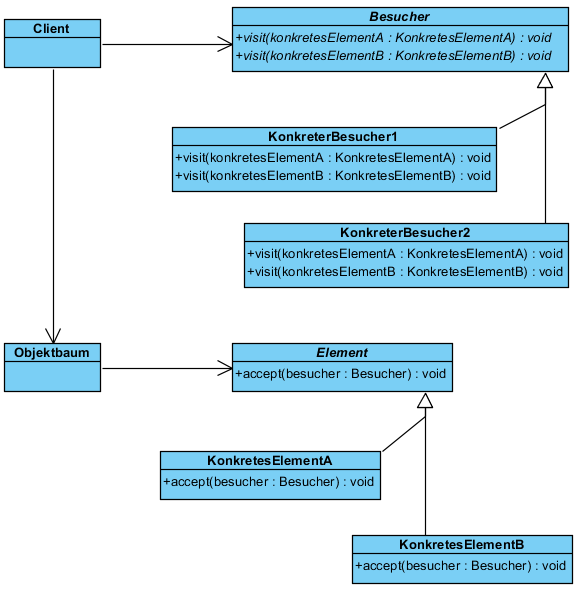
Vorteile des Patterns
Zunächst mag der doppelte Aufruf so aussehen, als ob durch das Visitor Pattern nur zusätzliche Komplexität in das Programm gebracht wird. Durch das Visitor-Pattern ist es jedoch möglich den Code für das Traversieren der Objektstruktur (beispielsweise des AST-Baumes) innerhalb der zu besuchenden Objekte unterzubringen, während die eigentliche Logik des Algorithmusses in die Besuchern eingebettet wird. Das Visitor-Pattern geht davon aus, dass sich die besuchten Objekte selten ändern, es jedoch relativ viele Änderungen in der Logik der Besucher gibt. Dementsprechend muss der Quellcode der zu besuchenden Objekte bei Änderungen in den Algorithmen nicht geändert werden, sondern dieser Code befindet sich innerhalb der Besucher. Der Code des Algorithmusses ist weiterhin nicht verteilt über alle zu besuchenden Objekte untergebracht, sondern befindet sich an einem Ort innerhalb der Besucher-Klasse.
Das Singleton-Pattern / Nur-ein-Objekt-zur-Laufzeit-Muster
Idee des Patterns
Häufig ist es so, dass man innerhalb eines Programmes sicherstellen will, dass eine Klasse nur genau einmal instantiiert wird. Alle Komponenten der Software greifen auf diese eine Instanz der Klasse gleichzeitig zu und teilen sich das Objekt. Dabei muss eine einfache Zugriffsmethode vorhanden sein.
Use-Cases eines solchen Patterns sind beispielsweise, wenn innerhalb einer Applikation genau eine Datenbankverbindung hergestellt werden soll, die von unterschiedlichen Teilen des Programmes zusammen genutzt wird. Logging wird häufig auch über ein Singletonpattern realisiert, welches den Zugriff auf die Logging-Datei hält und dafür sorgt, dass Logmeldungen serialisiert in diese offene Datei laufen. Andere Verwendungsmöglichkeiten sind zum Beispiel eine Instanz eines Hauptfensters einer Applikation oder eine Instanz einer Liste von Datenobjekten, die die Applikation verwaltet.
Grundlegende Implementierung des Patterns
Als UML2-Klassendiagramm lässt sich das Singleton-Pattern wie folgt darstellen:

Wird nun eine Instanz dieser Klasse benötigt, so ist das Vorgehen wie folgt:
- Der aufrufende Code ruft die statische Methode getInstance() auf. Für den Aufruf einer statischen Methode muss von der Klasse kein Objekt existieren.
- In der Methode getInstance() befindet sich eine Prüfung, ob das Objekt schon existiert. Wenn nicht, so wird der private Konstruktor aufgerufen und in der lokalen privaten Variable instance hinterlegt.
- Dann wird die lokale private Variable instance zurückgegeben.
Der Code der Methode getInstance() könnte dabei wie folgt aussehen:
|
1 2 3 4 |
if (instance == null) { instance = new Singleton(); } return instance; |
Dabei ist die Variable instance privat. Dies sichert diese Variable, so dass nicht zu irgendeinem Zeitpunkt innerhalb des Programmes wegen eines Programmierfehlers diese Variable direkt ausgelesen werden kann. Auch der Konstruktor ist privat. Dies bedeutet, dass er nur aus der Klasse selbst aufgerufen werden kann, wie es nämlich hier in der getInstance()-Methode geschieht.
Hier der Code des gesamten Singleton-Patterns:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public class Singleton { // Variable, die die einzige Instanz der Klasse hält. // Sie ist zugriffsgeschützt von außen und statisch. private static Singleton instance; // Privater Konstruktor. Ebeneso zugriffsgeschützt // von außen. private Singleton() {} // Einzige öffentliche Methode, die vom Rest des // Codes aufgerufen wird public static Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } } |
Betrachten wir nun den Code der getInstance()-Methode nochmals. Da immer geprüft wird, ob die instance-Variable belegt ist und nur, wenn sie nicht belegt ist, ein neues Singleton-Objekt angelegt wird und sie mit diesem belegt wird, kann kein zweites Singleton-Objekt angelegt werden. Die if-Bedingung kann auf der anderen Seite nur genau einmal wahr sein und in den if-Block springen, nämlich genau beim ersten Mal des Aufrufes der getInstance()-Methode. Wir haben also eine Möglichkeit erzeugt, nur ein Objekt dieser Klasse innerhalb des gesamten Programmes zuzulassen und damit die Singleton-Idee implementiert.
Multi-Threading
Wir haben gerade gesagt, dass unsere Implementierung des Singleton-Patterns unser System dazu zwingt, dass genau nur ein Objekt zur Laufzeit vorhanden ist. Dies ist auch bei einer Single-Thread-Umgebung, wo es nur einen Programmfaden gibt, der Fall. Arbeiten jedoch mehrere Threads im Programm, so kann es sein, dass der Thread in der getInstance()-Methode an Position (*) gestoppt wird:
|
1 2 3 4 5 |
if (instance == null) { // (*) instance = new Singleton(); } return instance; |
Ruft nun ein zweiter Thread die getInstance()-Methode auf, so ist die Variable instance weiterhin nicht belegt. Eine neue Instanz kann angelegt werden und diese der Variable zugewiesen werden. Die Instanz wird von der Methode in das Programm übergeben. Wenn nun jedoch wieder der erste Thread wieder Rechenzeit erhält, d.h. weiterläuft, so prüft dieser nicht mehr ob die Variable noch nicht belegt ist und der Konstruktor wird ein zweites Mal aufgerufen und die Variable instance überschrieben und diese zweite Instanz zurückgegeben. Innerhalb unseres Systems existieren nun genau zwei Instanzen des Singletons, was vermieden werden muss.
In dem folgenden Video ist das Problem an einem Live-Beispiel demonstriert:
Dieses Problem kann gelöst werden, indem man die Java Virtual Machine anweist, dass nur ein Thread diese Methode gleichzeitig betreten darf. Dies geschieht mit dem Keyword synchronized:
|
1 2 3 |
public static synchronized Singleton getInstance() { ... } |
Ein Problem bei dieser Lösung ist es nun jedoch, dass eine synchronized-Methode für jede Anfrage des Singleton-Objektes aufgerufen werden muss. Auch bei schon bestehendem Singleton-Objekt müssen Threads hintereinander gereiht werden. Zusätzlich hat die Java Virtual Machine Verwaltungsaufwand für diese synchronized-Methode. Aufgrund von beiden Tatsachen wird die Applikation langsam. Dabei ist dies gar nicht notwendig. Die Methode sollte nur dann synchronized sein, wenn die Instanz noch nicht erzeugt worden ist, d.h. der erste Aufruf der Methode noch nicht abgeschlossen ist.
Einen Ausweg aus diesem Performance-Problem bietet die statische Instantiierung des Singleton-Objektes. Dies tut der folgende Programmcode:
|
1 2 3 4 5 6 7 |
public class Singleton { private static Singleton instance = new Singleton(); private Singleton() {} public static Singleton getInstance() { return instance; } } |
Hier wird der Konstruktor der Singletonklasse schon zur Ladezeit durch den ClassLoader aufgerufen, der eine threadsichere Umgebung schafft. Erhält dann schließlich das Programm diese Klasse, so ist die instance-Variable schon vorbelegt. Wir müssen keine weitere Instantiierung durchführen.
Dieser Ansatz wird als der zu verfolgende Ansatz von der Oracle-Java-Entwicklungsgruppe bezeichnet. Mit Hilfe dieser einfachen Implementierung des Singleton-Patterns ist der Entwickler auf der sicheren ,,thread-safe“ Seite. Hingehen könnte es sein, dass das Programm zwar die Singleton-Klasse nutzt, jedoch die getInstance()-Methode niemals aufruft. Da das Singleton-Objekt in der Regel ein schwergewichtiges Objekt ist, gehen wertvolle Ressourcen dadurch verloren. Man nennt das Vorgehen dieser Implementierung mit der statischen Initialisierung ein Eager-Verhalten. Wir hätten jedoch gerne wieder ein Lazy-Verhalten, wie die Lösung mit der synchronized-Methode.
An dieser Stelle muss darauf aufmerksam gemacht werden, dass eine Singleton-Klasse, die noch andere Funktionalitäten hat, einen Bad Smell im Code darstellt, also ein Klassendesignproblem aufzeigt. Die Funktionalitäten sollten in zwei unterschiedliche Klassen ausgelagert werden, so dass das Singleton nicht sinnlos instantiiert werden muss.
Ist man aus irgendwelchen Gründen doch gezwungen, die Klasse so zu belassen, wie sie ist, so kann man trotzdem das Lazy-Verhalten implementieren, indem man Double-Checked-Locking (Doppelt-überprüfte Sperrung) verwendet. Der Code sieht dabei wie folgt aus:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public class Singleton { private volatile static Singleton instance; private Singleton() {} public static Singleton getInstance() { if (instance == null) { synchronized (Singleton.class) { if (instance == null) instance = new Singleton(); } } return instance; } } |
Der Unterschied zu der einfachen synchronized-Methode ist, dass hier die Methode nicht mehr synchronized ist, d.h. schnell aufgerufen werden kann. Ist dann die Instanz gesetzt, so wird nie wieder in den Ausführungsblock der äußeren If-Abfrage gesprungen, weshalb der dort beinhaltete synchronized-Block keine Rolle mehr spielt. Das Problem, dass ein Thread schon geprüft hat, ob die Variable noch unbesetzt ist und dann abgebrochen wird und durch einen anderen Thread in dem Moment die Variable belegt wird, wird umgangen, indem innerhalb des dargestellten synchronized-Blocks, die Variable instance nochmals geprüft wird. Zusätzlich muss für dieses Vorgehen die instance-Variable als volatile gekennzeichnet sein. Der CPU-Kern hat die Möglichkeit häufig benutzte Variablen nicht sofort wieder in den Hauptspeicher zu schreiben, sondern in sich zu halten, was einen Geschwindigkeitsvorteil bietet. Mit volatile wird sie jedoch angewiesen, die Variable immer sofort zurück zu schreiben, so dass ein anderer CPU-Kern, der einen anderen Thread bedient nicht eine nicht-aktuelle Speicherkopie der Variable im ungesetzten Zustand sieht.
Diese Double-Checked-Locking-Implementierung wird von vielen als ein Anti-Pattern gesehen. Dies ist zum einen deswegen der Fall, dass wie oben schon gesagt die Verwendung ein Zeichen ist, dass die Klasse zwei unterschiedlichen Zwecken dient. Zum anderen schleichen sich in die komplizierte Implementierung des Double-Checked-Lockings schnell Fehler ein, die mühsam zu finden sind.
Grenzen des Patterns
Dem Pattern sind Grenzen gesetzt, dass die Start-Up-Zeit eines Programmes eventuell sehr lang ist, da viele Singletons instantiiert werden müssen. Weiterhin wird das Singleton-Pattern häufig auch dort benutzt, wo eigentlich eine statische vorinitialisierte ausgereicht hätte. Hier wird der Code durch das Singleton-Pattern unnötig kompliziert.
Das Observer-Pattern / Beobachter-Muster
Idee des Patterns
Das Observer-Pattern oder zu Deutsch Beobachter-Muster ist eines der am meisten genutzten und bekanntesten Patterns. In diesem Muster gibt es zwei Akteure: Ein Subjekt, welches beobachtet wird und ein oder mehrere Beobachter, die über Änderungen des Subjektes informiert werden wollen.
Würde man ohne das Pattern eine solche Beobachtung implementieren, so müssten die beobachtenden Objekte in regelmäßigen Abständen das beobachtete Subjekt anfragen, ob sich sein Zustand geändert hat. Durch dieses Vorgehen wird unnötig Rechenzeit verschwendet.
Das Objektdiagramm sähe wie folgt aus, wenn das Observer-Pattern noch nicht angewendet worden ist:
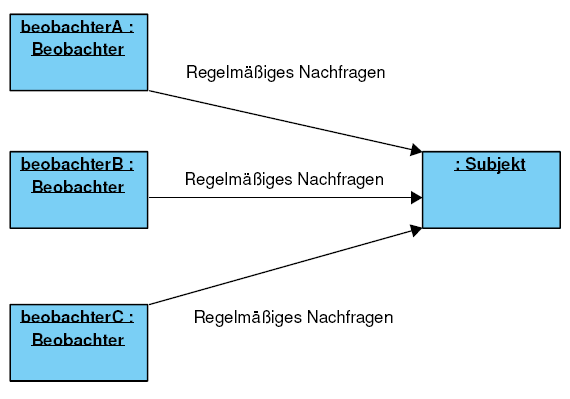
Die Idee des Observer-Patterns ist es nun, dem zu beobachtenden Subjekt die Aufgabe aufzutragen, die Beobachter bei einer Änderung über die Änderung zu informieren. Die Beobachter müssen nicht mehr in regelmäßigen Abständen beim Subjekt anfragen, sondern können sich darauf verlassen, dass sie eine Nachricht über eine Änderung erhalten.
Nun sieht das Objekt-Diagramm nach der Anwendung des Observer-Patterns wie folgt aus:
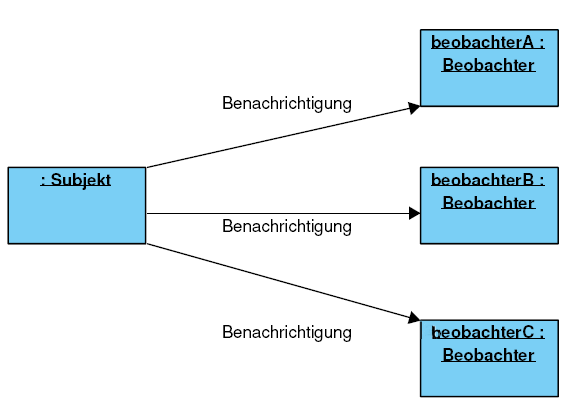
Registrierung, Benachrichtigung
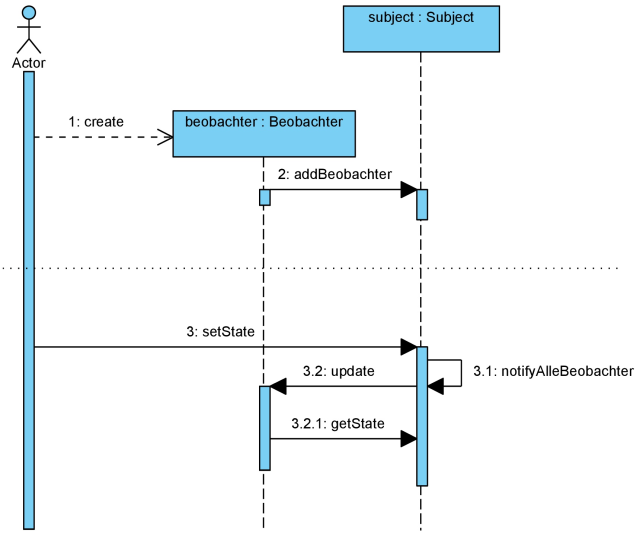
Beobachter müssen sich, bevor Sie von einem Subjekt benachrichtigt werden, bei diesem Subjekt registrieren. Jedes Subjekt verwaltet intern eine Liste von Beobachtern, die es bei einer Änderung seiner selbst nacheinander benachrichtigt. Neben der Methode zum Registrieren wird standardmäßig auch eine Methode zum Deregistrieren angeboten. Über diese Methode können sich Beobachter wieder abmelden, so dass sie aus der internen Liste entfernt werden und nicht mehr benachrichtigt werden.
Den Ablauf des Registrierens und der Benachrichtigung verdeutlicht das folgende Sequenzdiagramm (Es sei hier darauf hingewiesen, dass die Rücknachrichten in diesem Diagramm ausgelassen worden sind. Sie müssten zur Vollständigkeit ergänzt werden.):
Push und Pull
Wenn sich der Zustand des Subjektes ändert, ist für die meisten Beobachter der neue Zustand des Subjektes interessant. Hier lassen sich nun zwei Strategien umsetzen: Das Subjekt kann entweder den geänderten Zustand schon bei der Benachrichtigung des Beobachters mitsenden (Push-Methode). Oder aber der Beobachter kann, sobald er eine Nachricht erhält, dass sich der Zustand des Subjektes geändert hat, selbst aktiv werden und das Subjekt nach seinem neuen Zustand über einen Methodenaufruf befragen (Pull-Methode). Die Push-Methode hat zum Nachteil, dass es eventuell sein kann, dass das Subjekt Informationen sendet, die der Beobachter nicht verwerten kann oder will. Dies ist vor allen Dingen für sehr große Subjekte, die viele Zustände beinhalten der Fall. Auch muss für diesen Fall ein geeignetes Austauschformat, meist eine eigene Klasse, in deren Objekte der Zustand verpackt wird, definiert werden. Die Methode, dass die Beobachter das Subjekt befragen, hat zum Nachteil, dass entsprechende Methoden im Subjekt definiert werden müssen.
Abstrakte Darstellung als UML2-Klassendiagramm
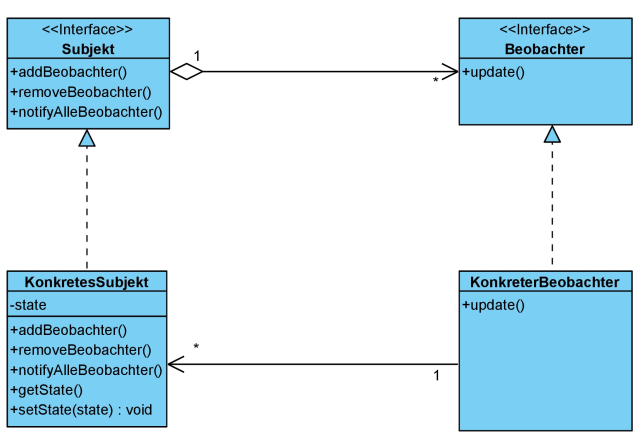
Quellcode in Java
Ohne die Java-API zu nutzen, kann das Observer-Pattern (Beobachter-Muster) wie folgt in Java ausimplementiert werden:
|
1 2 3 4 5 6 7 8 |
/** * Subjekt.java */ public interface Subjekt { public abstract void addBeobachter(Beobachter beobachter); public abstract void removeBeobachter(Beobachter beobachter); public abstract void notifyAlleBeobachter(); } |
|
1 2 3 4 5 6 |
/** * Beobachter.java */ public interface Beobachter { public abstract void update(); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
/** * KonkretesSubjekt.java */ import java.util.ArrayList; import java.util.List; public class KonkretesSubjekt implements Subjekt { List beobachterList = new ArrayList(); int state = 0; @Override public void addBeobachter(Beobachter beobachter) { this.beobachterList.add(beobachter); } @Override public void removeBeobachter(Beobachter beobachter) { this.beobachterList.remove(beobachter); } @Override public void notifyAlleBeobachter() { for (Beobachter beobachter : beobachterList) { beobachter.update(); } } public int getState() { return state; } public void setState(int state) { this.state = state; this.notifyAlleBeobachter(); } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
/** * KonkreterBeobachter.java */ public class KonkreterBeobachter implements Beobachter { private KonkretesSubjekt konkretesSubjekt; public KonkreterBeobachter(KonkretesSubjekt konkretesSubjekt) { this.konkretesSubjekt = konkretesSubjekt; // Durchführung der Registrierung beim übergebenen Subjekt this.konkretesSubjekt.addBeobachter(this); } @Override public void update() { int newState = konkretesSubjekt.getState(); // ...auf neuen Status reagieren } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
/** * Client.java */ public class Client { public static void main(String[] args) { // Erzeugung des Subjektes KonkretesSubjekt konkretesSubjekt = new KonkretesSubjekt(); // Erzeugung des Beobachters. Dabei wird // das Subjekt übergeben und registriert. KonkreterBeobachter konkreterBeobachter = new KonkreterBeobachter(konkretesSubjekt); // Zustandsänderung, Subjekt benachrichtigt // daraufhin die Beobachter konkretesSubjekt.setState(1); } } |
Zum Nachvollziehen ist der Source-Code auf GitHub unter ObserverPattern verfügbar.
Interfaces vs. Abstrakte Klassen
Die Java-API verfügt über ein Interface Observer und eine abstrakte Klasse Observable, die als Basis für das Observer-Pattern genutzt werden können. Durch diese Umsetzung des Observer-Patterns wird klar, dass das oben genannte Interface Subjekt auch durch eine abstrakte Klasse ersetzt werden kann. Dies abstrakte Klasse Observable innerhalb der Java-API beinhaltet schon Methoden, um Beobachter zu benachrichtigen, so dass Code gespart werden kann. Insgesamt ändert sich das Klassendiagramm wie folgt:
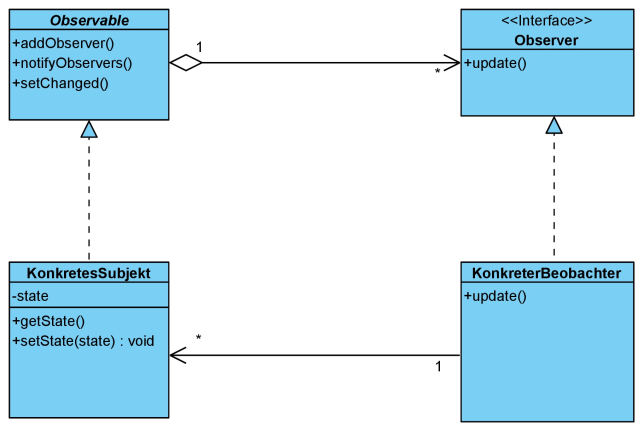
Der Quellcode der die Java-API nutzt, sieht wie folgt aus:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
/** * KonkretesSubjekt.java */ import java.util.Observable; public class KonkretesSubjekt extends Observable { int state = 0; public int getState() { return state; } public void setState(int state) { this.state = state; this.setChanged(); this.notifyObservers(); } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
/** * KonkreterBeobachter.java */ import java.util.Observable; import java.util.Observer; public class KonkreterBeobachter implements Observer { private KonkretesSubjekt konkretesSubjekt; public KonkreterBeobachter(KonkretesSubjekt konkretesSubjekt) { this.konkretesSubjekt = konkretesSubjekt; // Durchführung der Registrierung beim übergebenen Subjekt this.konkretesSubjekt.addObserver(this); } @Override public void update(Observable o, Object arg) { int newState = konkretesSubjekt.getState(); // ...auf neuen Status reagieren } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
/** * Client.java */ public class Client { public static void main(String[] args) { // Erzeugung des Subjektes KonkretesSubjekt konkretesSubjekt = new KonkretesSubjekt(); // Erzeugung des Beobachters. Dabei wird // das Subjekt übergeben und registriert. KonkreterBeobachter konkreterBeobachter = new KonkreterBeobachter(konkretesSubjekt); // Zustandsänderung, Subjekt benachrichtigt // daraufhin die Beobachter konkretesSubjekt.setState(1); } } |
Wichtig ist, dass die setChanged()-Methode aufgerufen wird, bevor die Observer benachrichtigt werden. Wird dies nicht getan, so reagiert die abstrakte Oberklasse Observable nicht auf die Änderung, weil sie denkt, dass sich das Subjekt nicht geändert hat.
Eine negative Seitenerscheinung dieser Implementierung ist es, dass das konkrete Subjekt von keiner weiteren Klasse mehr erben kann als der Klasse Observable. Dadurch muss auf eine Delegation ausweichen, wenn es schon vor der Einführung des Observer-Patterns hier eine Vererbung gegeben hat.
Zum Nachvollziehen ist der Source-Code auf GitHub unter ObserverPatternJDK verfügbar.
Das Beobachtermuster im Video erklärt
Java 8 Sprachfeatures
In Java 8 kommen zum Sprachstandard von Java sogenannte Default-Methoden hinzu, die in den Interfaces implementiert werden. Diese Default-Methoden eignen sich jedoch nicht für die Implementierung des Observer-Patterns, da innerhalb der Interfaces keine Klassen-Attribute deklariert werden können.
Wohl aber lassen sich Lambdas verwenden, um Beobachter kompakt darzustellen. Ein Lambda-Ausdruck ist eine weitere verkürzte Schreibweise einer anonymen Klasse. Hier definieren wir einen Beobachter als anonyme Klasse. Dies ist auch schon mit Java 7 möglich:
|
1 2 3 4 5 6 |
konkretesSubjekt.addBeobachter(new Beobachter() { @Override public void update() { System.out.println ("State changed"); } }); |
Dies kann in Java 8 mit einem Lambda-Ausdruck weiter verkürzt werden:
|
1 |
konkretesSubjekt.addBeobachter(() -> System.out.println ("State changed")); |
Die beiden runden Klammern () dienen zur Parameterübergabe. Hier können Parameter, die bei dem Aufruf des Beobachters übergeben werden, angegeben werden. Dazu erweitern wir zunächst das Interface Beobachter
|
1 2 3 4 5 6 |
/** * Beobachter.java */ public interface Beobachter { public abstract void update(int pushvalue); } |
Nun können wir einen Lambda-Ausdruck wie folgt formulieren:
|
1 2 |
konkretesSubjekt.addBeobachter((pushvalue) -> System.out.println ("State changed to " + pushvalue)); |
Sowohl beim Nutzen einer anonymen Klasse, wie auch bei der Nutzung eines Lambda-Ausdruckes entsteht das Problem, dass wir keine Variable mehr erhalten, in welcher das Objekt des Beobachters vorhanden ist. Wir können den Beobachter nicht mehr vom Subjekt abmelden, da wir keine Referenz haben. Dieses Problem lässt sich jedoch umgehen, indem wir bei der Anmeldung des Beobachters den angemeldeten Beobachter selbst als Rückgabewert zurückgeben. Dafür erweitern wir zunächst das Interface für das Subjekt, so dass addBeobachter ein Objekt mit dem Typ Beobachter zurück gibt:
|
1 2 3 4 5 6 7 |
/** * Subjekt.java */ public interface Subjekt { public abstract Beobachter addBeobachter(Beobachter beobachter); /* ... weitere Methodenköpfe ... */ } |
Dann erhalten wir den Beobachter sowohl bei der Registrierung durch eine anyonyme Klasse, wie auch durch einen Lambda-Ausdruck:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Beobachter anonymeKlasseBeobachter = konkretesSubjekt.addBeobachter(new Beobachter() { @Override public void update() { System.out.println ("State changed"); } }); Beobachter lambdaBeobachter = konkretesSubjekt.addBeobachter(() -> System.out.println ("State changed")); // Diese Beobachter können wir nun wieder deregistrieren, // da wir eine Objektreferenz halten konkretesSubjekt.removeBeobachter(anonymeKlasseBeobachter); konkretesSubjekt.removeBeobachter(lambdaBeobachter); |
Zum Nachvollziehen ist der Source-Code auf GitHub unter ObserverPatternJDK8 verfügbar.
Hooks als eine Vereinfachung des Patterns für nur einen Observer
Ein Hook ist eine Methode, welche in der Oberklasse einer Klasse mit einem leeren Methodenrumpf implementiert ist. Damit ist die Methode nicht abstrakt, sondern hat nur keinen Code, der bei ihrer Ausführung durchlaufen wird. Eine Unterklasse kann, muss jedoch nicht, diese Methode überschreiben.
Mit einem Hook kann sich eine Unterklasse eines Subjektes wie ein Beobachter verhalten, muss es aber nicht.
In JavaScript wird das Hook-Konzept massiv für Beobachter genutzt, indem dynamisch Methoden von DOM-Objekten überschrieben werden. So kann genau eine Funktion beispielsweise bei einem Klick auf ein DOM-Element aufgerufen werden.
Probleme des Observer-Patterns und deren Lösung durch AOP
Eines der Probleme des Observer-Patterns ist es, dass eventuell bei einer Zustandsänderung einer Modelklasse sehr viele Observer benachrichtigt werden. Die Beobachter brauchen jeder für sich Rechenzeit, um beispielsweise ihre Anzeige aktualisieren zu können, was das Programm verlangsamt. Wenn nun dieser neue angezeigte Zustand nur ein Zwischenzustand ist, wie dies beispielsweise bei einem Hinzufügen von einem Element nach dem anderen in eine Liste geschieht, wäre die Aktualisierung der Anzeige überhaupt nicht nötig gewesen. Dies kann sich negativ auf die Performance des Gesamtprogrammes auswirken, bis sogar dahin, dass das Programm unbenutzbar wird und nur noch „flackert“. Hier gibt AOP Abhilfe. AOP kann den dynamischen Kontrollfluss des Programmes mit Hilfe eines Aspektes überwachen und feststellen, dass ein Kontrollflussblock verlassen worden ist und dass eine Serie von Änderungen abgeschlossen ist. Änderungsmitteilungen können zurückgehalten werden, bis dieser Moment erreicht ist.
Auch das Problem, dass bei einer allgemeinen Implementierung, wie in der Java API vorhanden, eine Vererbung einer abstrakten Klasse geschehen muss, lässt sich mit Hilfe der aspektorientierten Programmierung lösen. So lässt sich die abstrakte Implementierung des Observer-Patters komplett von seiner konkreten Implementierung trennen, ohne Nachteile in Kauf nehmen zu müssen. Dabei wird ein Aspekt erstellt, der sämtliche Observable-Methoden des Observer-Patterns in die entsprechende konkrete Klasse des Observable injiziert.
Motivation Refactoring
Eine Weiterentwicklung eines Projektes führt natürlicherweise immer dazu, dass vorhandener Code immer unaufgeräumter wird. Ein Refactoring ist ein Umbau dieses unübersichtlichen Codes in übersichtlicheren. Äußerlich betrachtet scheint dies keinen neuen Nutzen zu bringen. Von der Programmierersicht ist ein Refactoring jedoch essentiell. An dieser Stelle seien einige Motivationen für ein Refactoring aufgezeigt:
Gründe für ein Refactoring und damit einen übersichtlichen Quellcode:
- Programmierer des Teams können den vorhandenen Code besser verstehen und demzufolge mit diesem besser umgehen. Dies hat mehrere Dinge zur Folge:
- Eine bessere Verständnis des Codes führt dazu, dass neue Features schneller implementiert werden können. Demzufolge kann man ein Refactoring des Codes als Vorbereiten des Codes für Neuimplementierungen sehen.
- Da eine bessere Übersichtlichkeit entsteht, werden weniger Bugs eingebaut, bzw. vorhandene Bugs werden offensichtlich, da der Code verstanden wird.
- Auch können Programmierer, die neu dem Team zustoßen, sich in den schon vorhandenen Code besser einarbeiten.
- Programmieren ist eine geistig anstrengende Arbeit. Zufriedene Programmierer arbeiten besser.
- Gibt es immer wieder Verständnissprobleme mit dem Code – wobei das Programm dann teilweise mühsam debuggt werden muss, um dessen Funktionalität zu verstehen – nähert sich der Programmierer seine Frustationsgrenze. Dies kann in ein inneres Aufgeben münden, wo die Software hoffnungslos verloren ist.
- Programmieren muss einen gewissen Spaß bereiten. Vor allen Dingen sollte der Programmierer die Frucht seiner Arbeit sehen und nicht in neu auftretenden Bugs ersticken. Ordentlicher Code gibt Programmierern Erfolgserlebnisse, so dass schnell und zügig entwickelt werden kann. Die Agilität der Software ist so hoch.
Gründe, die gegen ein Refactoring sprechen:
- Es muss zusätzliche Zeit investiert werden. Für Programmcode, der nicht weiterentwickelt werden soll und in Zukunft ersetzt werden soll, lohnt sich dies nicht. Bei Projekten, die allerdings noch weiterentwickelt werden, entsteht ein Vielfaches an Zeitersparnis am Ende der Implementierungsphase.
- Ggf. können durch ein Refactoring Fehler dem Code hinzugefügt werden. Hiergegen ist entgegen zu wirken, indem zunächst Tests entwickelt werden, die den vorhandenen Code auf korrekte Arbeitsweise prüfen. Vor und nach dem Refactoring müssen diese Tests erfolgreich laufen. Positiver Nebeneffekt: Der Code der Tests kann behalten werden und auch für nachfolgende Entwicklungsvorhaben weiter verwendet werden.
- Es entstehen durch bestimmte Refactorings sehr viele Änderungen im Code beispielsweise durch Umbenennen von Methoden. Resultat ist, dass abschließend Branches des Projektes schwer zusammen zu mergen sind.
- Programmierer sind evtl. gewöhnt immer an der gleichen Stelle zu schauen, um neue Funktionsmerkmale eines Programms zu implementieren. Evlt. werden diese kurzfristig verwirrt, wenn bekannte Strukturen plötzlich verändert sind.
Refactoring – Eine Einführung
Während meiner Studienzeit entstand folgendes Plakat zum Thema Refactoring, welches das Thema auf einer Seite zusammen fasst. Ein Klick auf das Bild zeigt eine Vollansicht:

Im folgenden sind die Folien des Vortrages wiedergegeben: