Archiv für die Kategorie „Refactoring“
 Motivation Refactoring
Motivation Refactoring
Eine Weiterentwicklung eines Projektes führt natürlicherweise immer dazu, dass vorhandener Code immer unaufgeräumter wird. Ein Refactoring ist ein Umbau dieses unübersichtlichen Codes in übersichtlicheren. Äußerlich betrachtet scheint dies keinen neuen Nutzen zu bringen. Von der Programmierersicht ist ein Refactoring jedoch essentiell. An dieser Stelle seien einige Motivationen für ein Refactoring aufgezeigt:
Gründe für ein Refactoring und damit einen übersichtlichen Quellcode:
- Programmierer des Teams können den vorhandenen Code besser verstehen und demzufolge mit diesem besser umgehen. Dies hat mehrere Dinge zur Folge:
- Eine bessere Verständnis des Codes führt dazu, dass neue Features schneller implementiert werden können. Demzufolge kann man ein Refactoring des Codes als Vorbereiten des Codes für Neuimplementierungen sehen.
- Da eine bessere Übersichtlichkeit entsteht, werden weniger Bugs eingebaut, bzw. vorhandene Bugs werden offensichtlich, da der Code verstanden wird.
- Auch können Programmierer, die neu dem Team zustoßen, sich in den schon vorhandenen Code besser einarbeiten.
- Programmieren ist eine geistig anstrengende Arbeit. Zufriedene Programmierer arbeiten besser.
- Gibt es immer wieder Verständnissprobleme mit dem Code – wobei das Programm dann teilweise mühsam debuggt werden muss, um dessen Funktionalität zu verstehen – nähert sich der Programmierer seine Frustationsgrenze. Dies kann in ein inneres Aufgeben münden, wo die Software hoffnungslos verloren ist.
- Programmieren muss einen gewissen Spaß bereiten. Vor allen Dingen sollte der Programmierer die Frucht seiner Arbeit sehen und nicht in neu auftretenden Bugs ersticken. Ordentlicher Code gibt Programmierern Erfolgserlebnisse, so dass schnell und zügig entwickelt werden kann. Die Agilität der Software ist so hoch.
Gründe, die gegen ein Refactoring sprechen:
- Es muss zusätzliche Zeit investiert werden. Für Programmcode, der nicht weiterentwickelt werden soll und in Zukunft ersetzt werden soll, lohnt sich dies nicht. Bei Projekten, die allerdings noch weiterentwickelt werden, entsteht ein Vielfaches an Zeitersparnis am Ende der Implementierungsphase.
- Ggf. können durch ein Refactoring Fehler dem Code hinzugefügt werden. Hiergegen ist entgegen zu wirken, indem zunächst Tests entwickelt werden, die den vorhandenen Code auf korrekte Arbeitsweise prüfen. Vor und nach dem Refactoring müssen diese Tests erfolgreich laufen. Positiver Nebeneffekt: Der Code der Tests kann behalten werden und auch für nachfolgende Entwicklungsvorhaben weiter verwendet werden.
- Es entstehen durch bestimmte Refactorings sehr viele Änderungen im Code beispielsweise durch Umbenennen von Methoden. Resultat ist, dass abschließend Branches des Projektes schwer zusammen zu mergen sind.
- Programmierer sind evtl. gewöhnt immer an der gleichen Stelle zu schauen, um neue Funktionsmerkmale eines Programms zu implementieren. Evlt. werden diese kurzfristig verwirrt, wenn bekannte Strukturen plötzlich verändert sind.
Refactoring – Eine Einführung
Während meiner Studienzeit entstand folgendes Plakat zum Thema Refactoring, welches das Thema auf einer Seite zusammen fasst. Ein Klick auf das Bild zeigt eine Vollansicht:

Im folgenden sind die Folien des Vortrages wiedergegeben:




















Refactoring mit Eclipse Step4Step
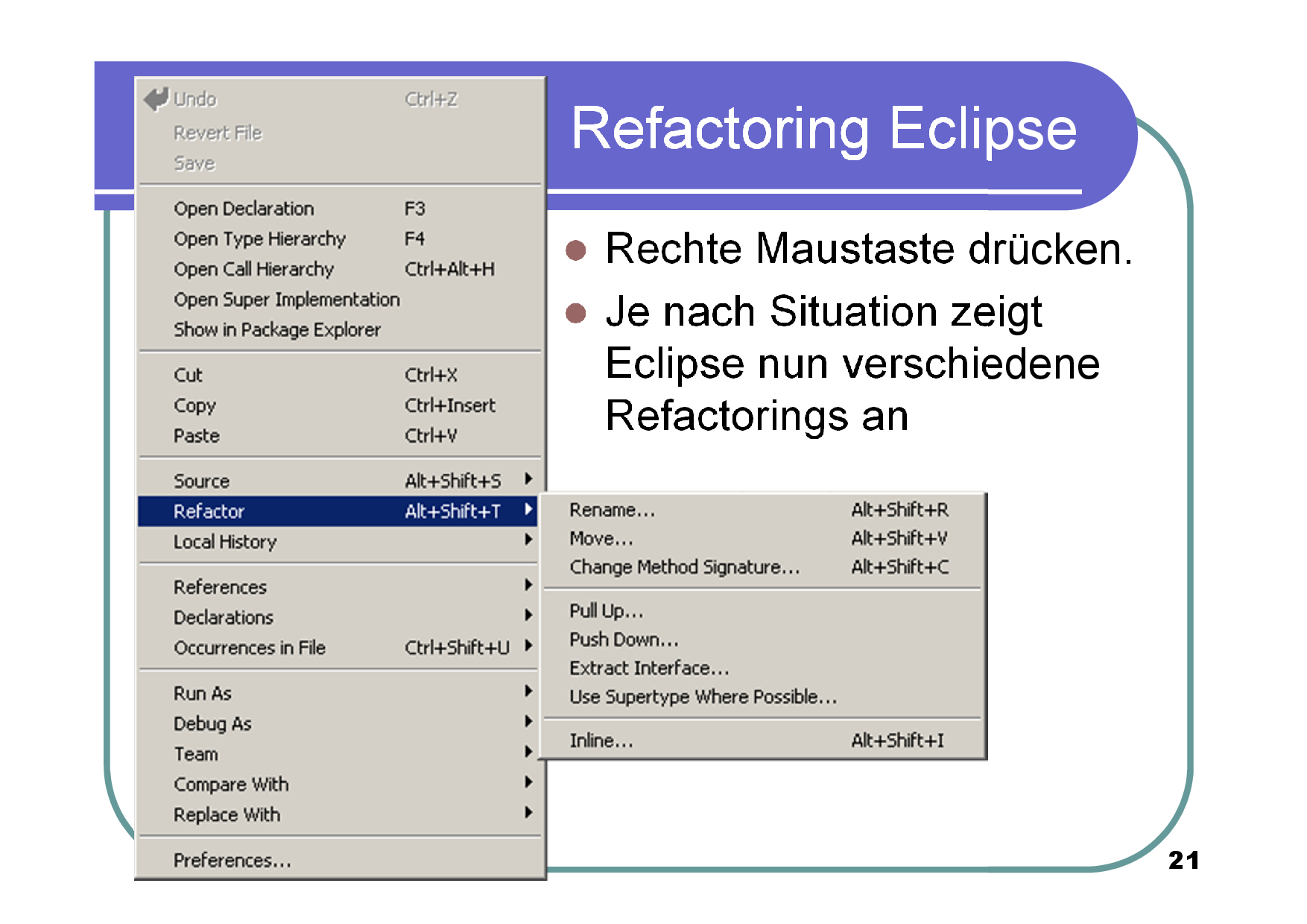
Im Folgenden möchte ich gerne einige der Refactoring-Funktionalitäten von Eclipse demonstrieren. Für das Refactoring wird ein JUnit-Test, so wie es Ziel der eXtreme-Programming-Methodik ist, benutzt, um zu prüfen, ob die originale Funktionalität noch vorhanden ist. Die Anleitung demonstriert die Fähigkeiten der Eclipse-Entwicklungsumgebung das Rafactoring mit JUnit zu unterstützen, zeigt jedoch im letzten Schritt auch Grenzen auf, so wieder ein händisches Vorgehen vonnöten ist.
Vielfach wurden die Sourcen der Anleitung erwünscht. Das Projekt zu Beginn befindet sich in vorRefactoring.zip, das Projekt nach allen Refactoringschritten befindet sich in nachRefactoring.zip.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
/** * AdressAusgabe.java * Klasse zur Ausgabe eines Adressbucheintrages * @author Christoph Tornau * */ public class AdressAusgabe { public String name; public String vorname; public String strasse; public String plz; public String ort; public AdressAusgabe(String name, String vorname, String strasse, String plz, String ort ) { this.name = name; this.vorname = vorname; this.strasse = strasse; this.ort = ort; this.plz = plz; } public String toString() { String output = ""; output += ("***"); output += (name); for (int i= name.length() + 3; i<30; i++) output += ("*"); output += ("\n"); output += ("***"); output += (vorname); for (int i= vorname.length() + 3; i<30; i++) output +=("*"); output += ("\n"); output += ("***"); output += (strasse); for (int i= strasse.length() + 3; i<30; i++) output += ("*"); output += ("\n"); output += ("***"); output += (plz); for (int i= plz.length() + 3; i<30; i++) output +=("*"); output += ("\n"); output += ("***"); output += (ort); for (int i= ort.length() + 3; i<30; i++) output +=("*"); output += ("\n"); output += ("***"); output += (""); for (int i= "".length() + 3; i<30; i++) output +=("*"); output += ("\n"); return output; } /** * Main method * @param args */ public static void main(String[] args) { AdressAusgabe myAdresse1 = new AdressAusgabe ("Maier","Hans", "Musterstrasse 1","11111","Musterstadt"); System.out.println(myAdresse1); AdressAusgabe myAdresse2 = new AdressAusgabe ("Gustav","Morgan", "Pappelallee 15","53122","Bonn"); System.out.println(myAdresse2); } } |
An der Beispielklasse fallen uns folgende Bad-Smells sofort auf:
- Der Code für die Ausgabe ist in mehrfacher Ausführung vorhanden.
- Anscheindend wurde darauf verzichtet in eine extra Datenklasse zu kapseln. Alles ist in einer Klasse geschrieben. Man sollte auf jeden Fall trennen.
- Felder können von außen gelesen und geschrieben werden. Es gibt keine Getter- und Setter-Methoden.
Der Code verfügt über einen JUnit-Test, wie folgender Screenshot zeigt:
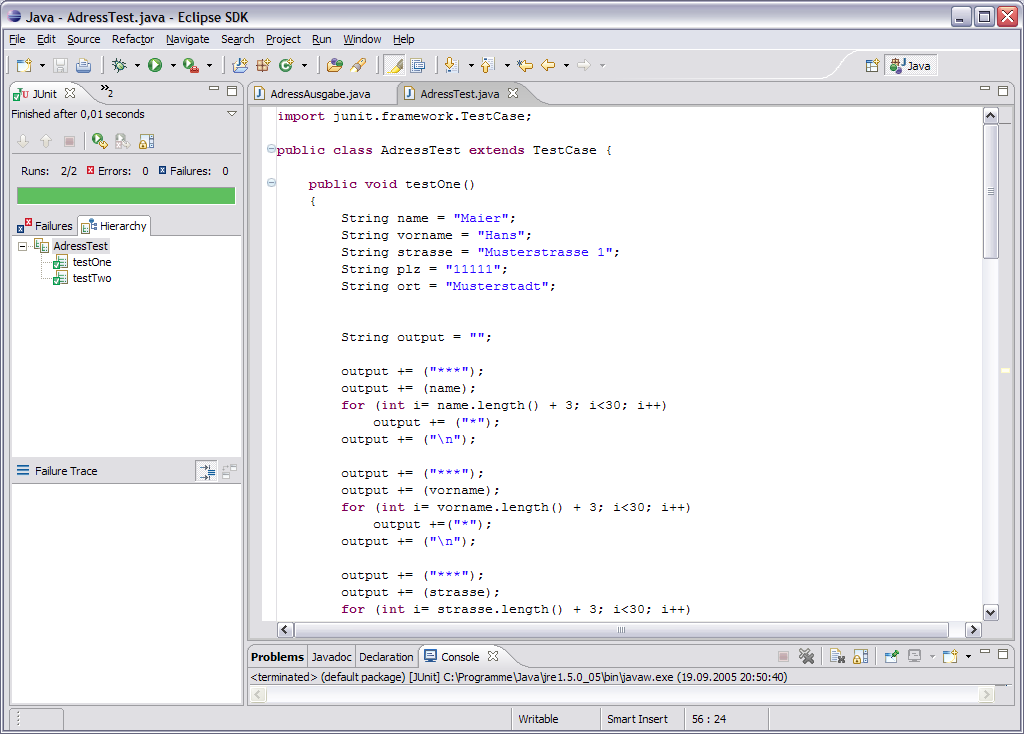
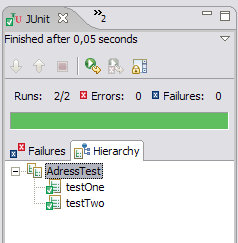
Wir führen nun folgende Refactorings nacheinander durch. Nach den einzelenen Schritten führen wir jedesmal einen Test mit JUnit durch. Ds Refactoring kann nur fortgeführt werden, wenn der Balken grün bleibt. Ansonsten haben wir einen Fehler gemacht. Hier der grüne Balken:
1. Extract Method:
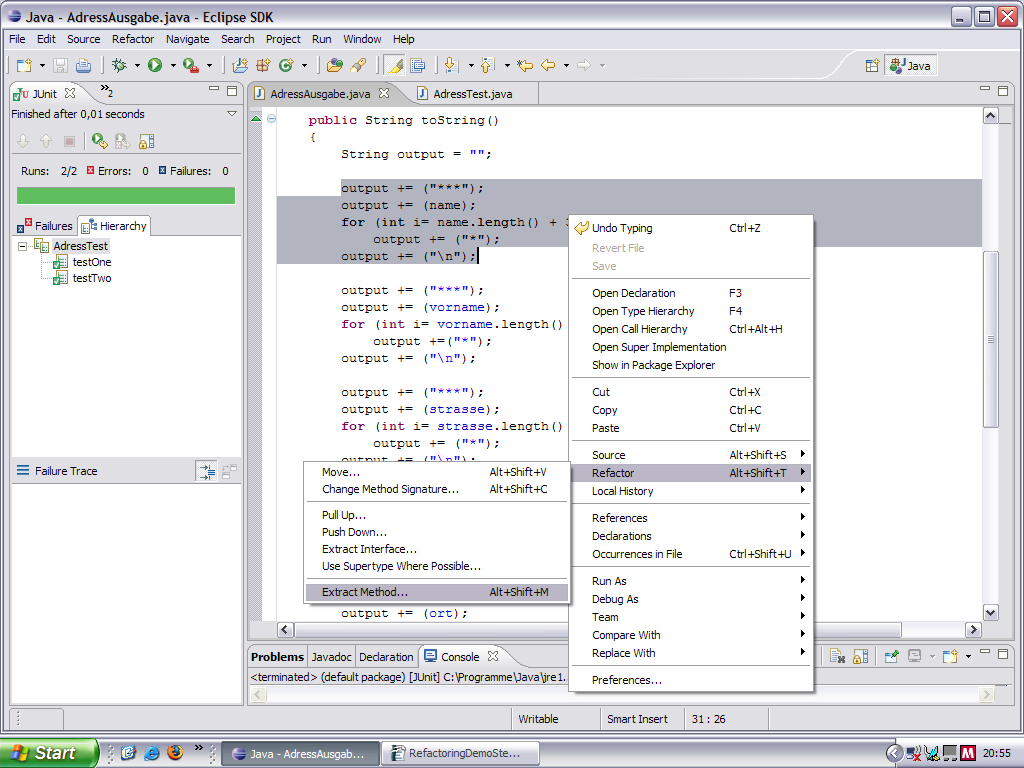
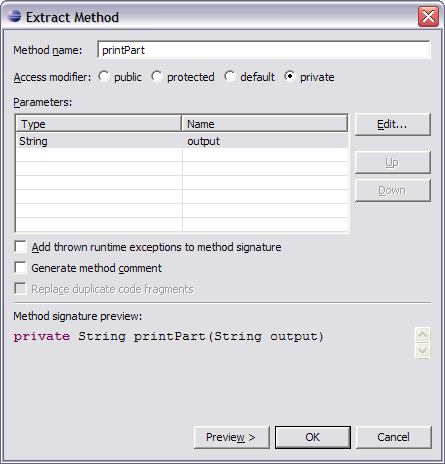
Nun entsteht eine neue Methode im Code:
|
1 2 3 4 5 6 7 8 |
private String printPart(String output) { output += ("***"); output += (name); for (int i= name.length() + 3; i<30; i++) output += ("*"); output += ("\n"); return output; } |
Wir sehen, dass diese Methode als „private“ deklariert ist und den output-String sowohl bekommt als auch wieder ausgibt. Nach dem Extrahieren der Methode können wir die JUnit-Tests ausführen, um zu prüfen, ob die Programmfunktionalität zerstört worden ist.
2. Ändern des Methoden-Aufrufs
Wir wollen den String, welcher übergeben wird, in die Ausgabe statt „name“ einbauen. Gleichzeitig wollen wir den Originalstring nicht mehr übergeben:
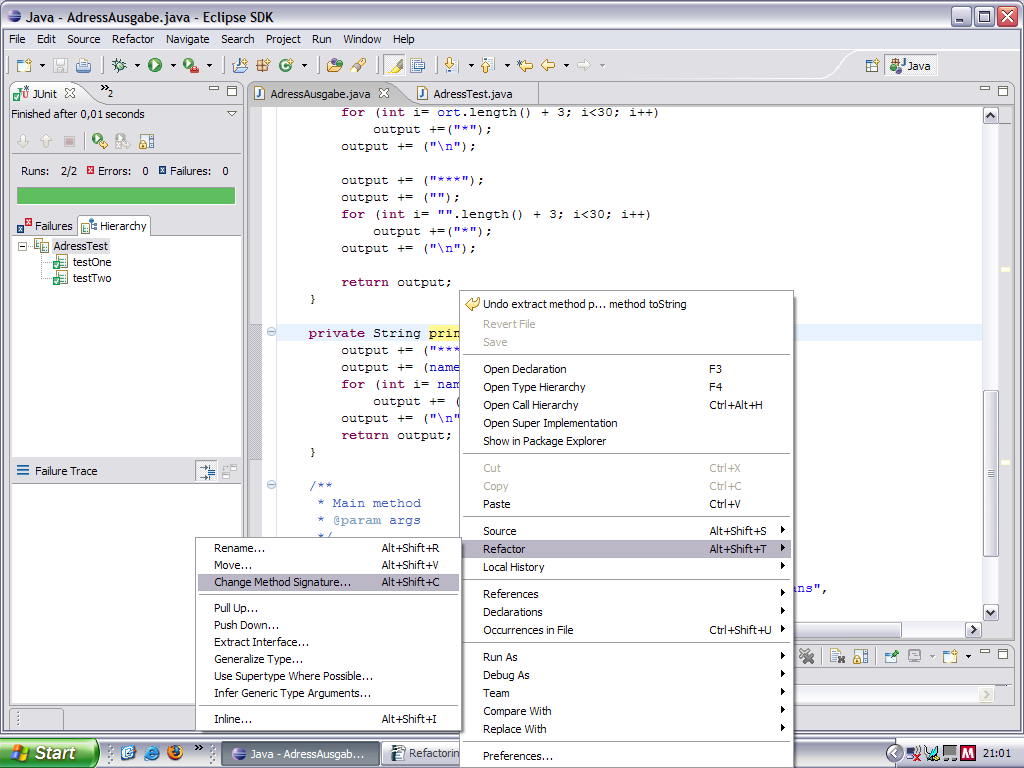
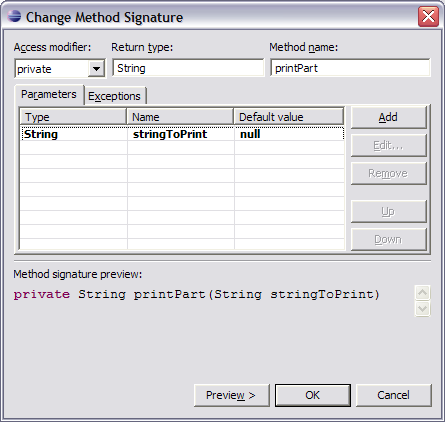
Nun gibt es einige Fehlermeldungen:
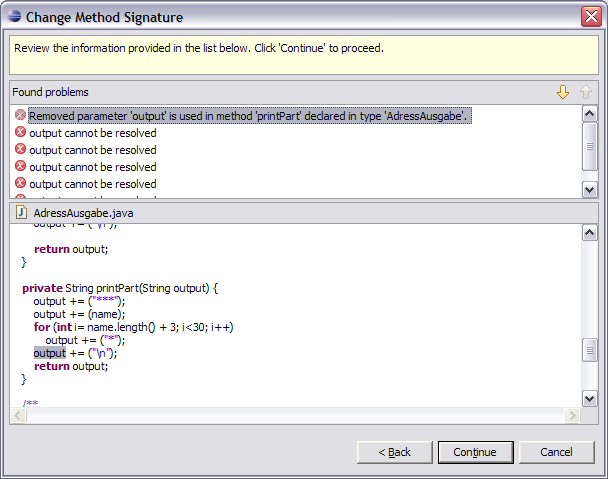
Wir ignorieren diese und ändern den Code per Hand um:
|
1 2 3 4 5 6 7 8 9 10 |
private String printPart(String stringToPrint) { String output = ""; output += ("***"); output += (stringToPrint); for (int i= stringToPrint.length() + 3; i<30; i++) output += ("*"); output += ("\n"); return output; } |
Ebenso ändern wir den Methodenaufruf per Hand um in
|
1 |
output = printPart(name); |
Nun können wir per Hand die hinzugefügte Methode ändern und elimieren so den dupplizierten Code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public String toString() { String output = ""; output += printPart(name); output += printPart(vorname); output += printPart(strasse); output += printPart(plz); output += printPart(ort); output += printPart(""); return output; } |
Nachdem wir dies durchgeführt haben, müssen wir wiederum die JUnit-Tests ausführen und erhalten als Ergebnis, dass der Code immernoch lauffähig ist.
3. Neue Klasse erzeugen und Methoden bewegen
Nun möchten wir gerne eine Datenklasse erzeugen, um die Daten von der Hauptklasse abzutrennen:
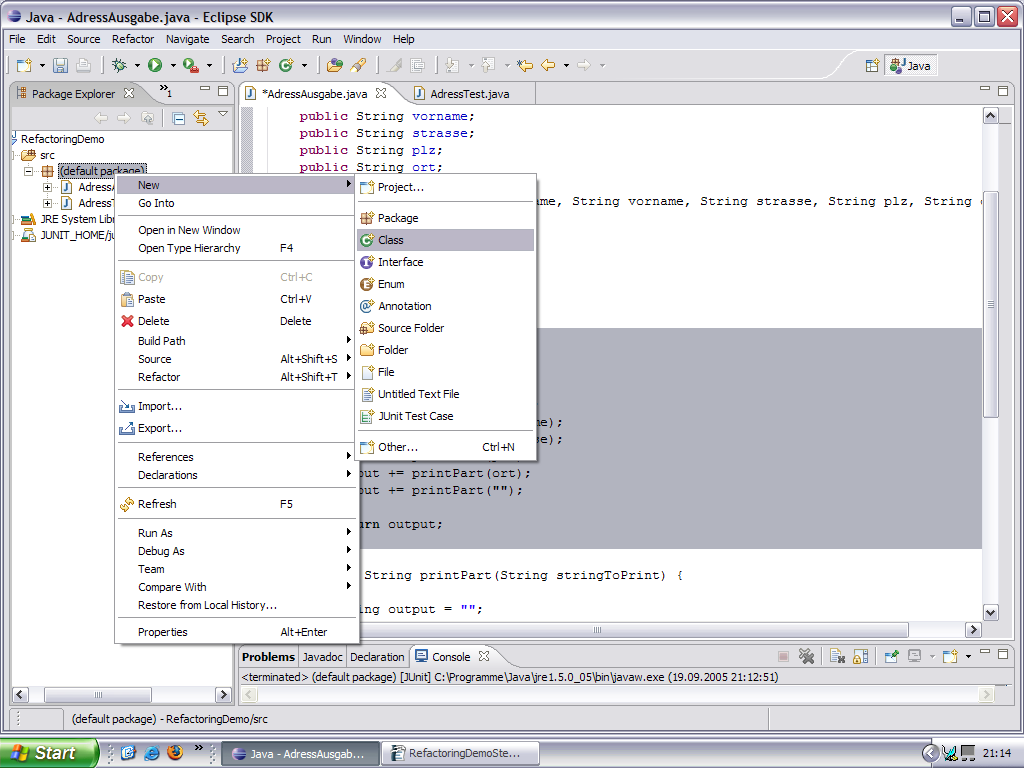
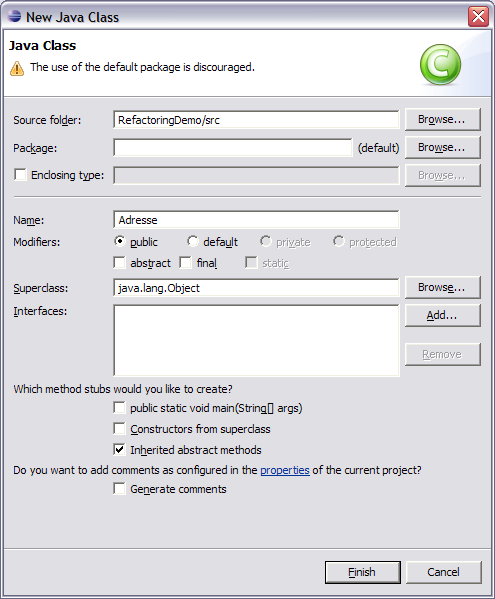
Wir bewegen zunächst die Methode printPart, nachdem wir deren Methoden Signatur etwas geändert haben:
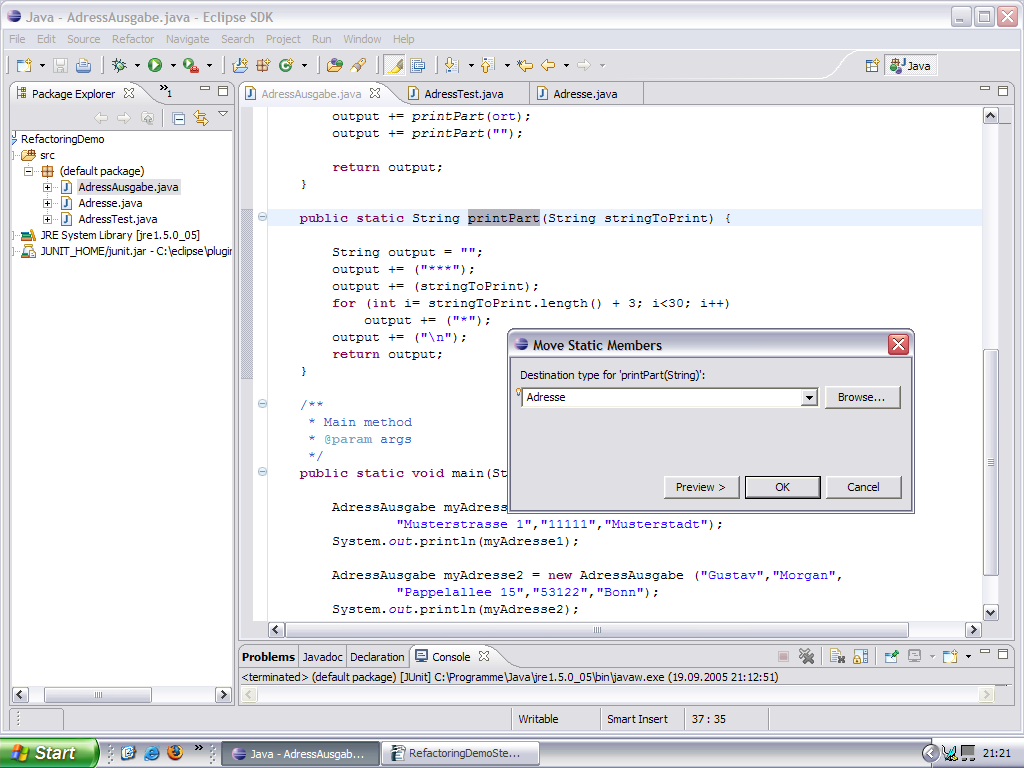
Unser Code ändert sich automatisch mit
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public String toString() { String output = ""; output += Adresse.printPart(name); output += Adresse.printPart(vorname); output += Adresse.printPart(strasse); output += Adresse.printPart(plz); output += Adresse.printPart(ort); output += Adresse.printPart(""); return output; } |
Leider können wir die restlichen Methoden mit Eclipse nicht automatisch verschieben, weshalb wir sie per Hand verschieben, so dass die neue Klasse wie folgt aussieht:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
public class Adresse { public String name; public String vorname; public String strasse; public String plz; public String ort; public Adresse(String name, String vorname, String strasse, String plz, String ort ) { this.name = name; this.vorname = vorname; this.strasse = strasse; this.ort = ort; this.plz = plz; } public String toString() { String output = ""; output += Adresse.printPart(name); output += Adresse.printPart(vorname); output += Adresse.printPart(strasse); output += Adresse.printPart(plz); output += Adresse.printPart(ort); output += Adresse.printPart(""); return output; } public static String printPart(String stringToPrint) { String output = ""; output += ("***"); output += (stringToPrint); for (int i= stringToPrint.length() + 3; i<30; i++) output += ("*"); output += ("\n"); return output; } } |
Hier hinkt nun unser JUnit-Test. Der Grund hierfür ist, dass sich der Klassenname der zu prüfenden Klasse geändert hat, da die Funktionalität per Hand verschoben worden ist. In diesem Fall dürfen wir jedoch unseren JUnit-Test anpassen, indem wir dort den Klassennamen ändern.
Wir setzen die Methode printPart wieder privat.
Noch immer sind die Felder „public“ Wir wenden Encapsulate Field an.
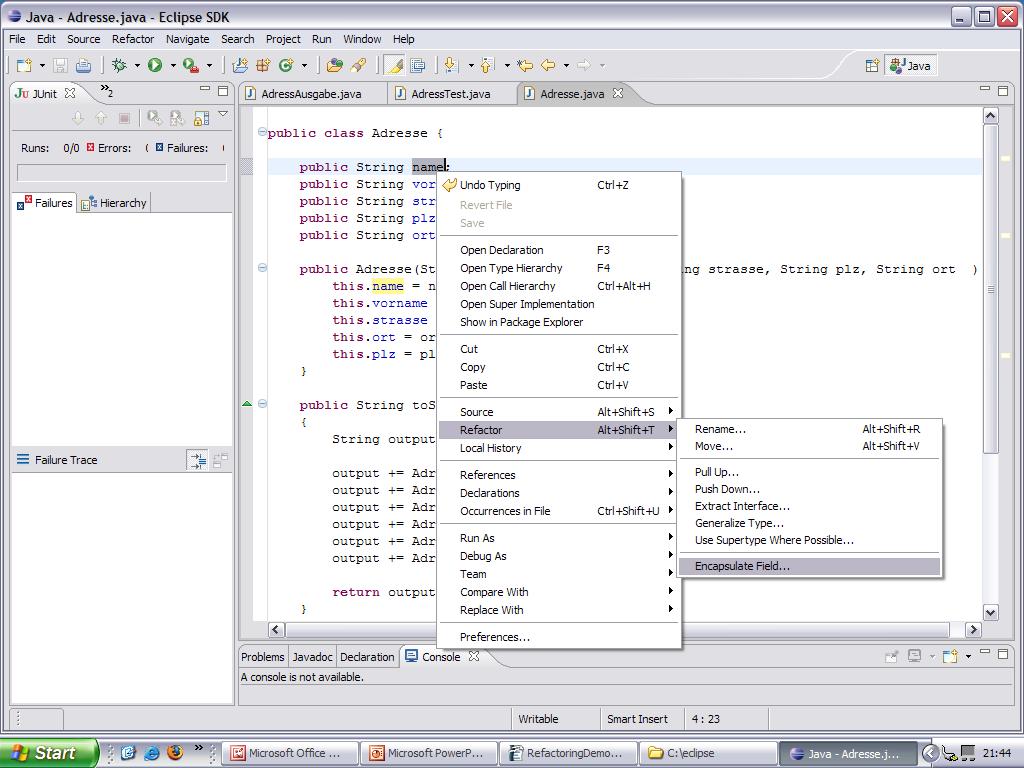
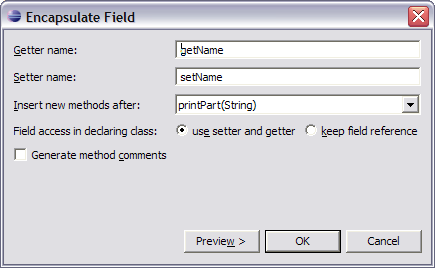
Wir führen die JUnit-Tests nochmals durch. Wir sehen, dass der Balken weiter grün ist. Das Refactoring war erfolgreich und wir haben viel schöneren Code erhalten.